성능
시간복잡도
시간복잡도란?
프로그래밍을 할 때는 언제나 비용을 신경써야한다. 그 비용 중 하나가 코드가 돌아가는데 필요한 실행시간일 것이다. 그리고 이러한 실행시간을 시간복잡도라고도 부른다.
시간복잡도를 정확히 예측할 필요는 없지만 그 시간을 개략적으로 예측하는 것은 필요하다.
시간복잡도를 표현할 때는 Big-O기법을 사용하는데, 이는 가장 빠르게 증가하는 항만을 고려하는 표기법이다. 즉, 가장 영향력이 큰 부분에 대해서만 시간 복잡도를 고려하는 것이다.
시간 복잡도는 대표적으로 다음 일곱가지 종류로 나눠볼 수 있다.
시간복잡도(증가함수) 종류

| 종류(빅오표기법) | 명칭 | 설명 | 대표사례 | 문제크기가 100배 커질 때 예상 소요시간 |
|---|---|---|---|---|
| O(1) | 상수시간 | 고정된 수의 문장을 실행하므로 문제의 크기에 따라 시간이 변하지 않는다. | print(1+2) | 불변 |
| O(log N) | 로그시간 | 실행시간이 로그함수로 늘어나며 상수시간보다 그다지 느리지 않다. | binary search | |
| O(N) | 선형시간 | 실행시간이 문제크기와 정비례하다. | for i in range: | 몇 초 |
| O(NlogN) | 로그 선형시간 | 선형로그 증가도 알고리즘으로 효율적으로 풀 수 있는 문제들이 많으며, 이차함수 증가도로 해결할 수 있는 문제보다 더 큰 규모의 문제를 해결할 수 있다. | merge sort | 몇 분 |
| O(N^2) | 이차시간 | 전형적으로 내포된 for루프를 가지고 있으며, n개 요소의 모든 쌍에 일정 연산을 수행한다. | 이중루프, 삽입 정렬 | 몇 시간 |
| O(N^3) | 삼차시간 | 삼중 내포 루프 | 몇 주 | |
| O(2^n) | 지수 시간 | 지수함수는 매우 느리므로 문제가 클 땐 이런 프로그램을 실행하면 안된다. | 모든 부분집합 검사 | 무한 시간 |
실행시간이 이차, 삼차, 지수까지 간다면 아무리 좋은 컴퓨터라도 실행시간에 있어서의 성능향상을 기대할 수 없을 것이다.
따라서 성능을 예측하고 이를 개선하기 위한 방법들을 강구하는 것이 필요하다.
그렇다고 성능에 너무 많은 신경을 쓰기보다는 코드를 깔끔하고 정확하게 하는 것이 최우선 순위일 것이다. 그러나 좋은 코드 몇 줄을 추가했을 때 실행 시간 향상이 상당히 절약된다면 조금은 더 복잡한 코드를 사용해 성능을 올릴필요가 있다. 즉 성능과 가독성의 트레이드오프를 맞추는 것이 중요할 것이다.
시간 복잡도 분석 시 주의할 점
성능을 분석할 때 모순되거나 잘못된 결과가 나오지 않기 위해선 다음과 같은 사항들을 알아두고 있어야한다.
- 각 명령을 실행하는 데 늘 똑같은 시간이 걸린다고 가정하지 말자.
- 예를 들어, 메모리에 효율적으로 접근하기 위해 캐시기법을 사용한다면, 이때 큰 배열 내에서 멀리 떨어진 요소에 접근할 땐 시간이 더 많이 걸릴 수 있다.
- 내부 루프가 실행시간에 늘 큰 영향을 끼치는 것은 아닐 수 있다.
- 오히려 내부 루프 바깥에 상당한 양의 코드를 실행하는 프로그램이 있을 수 있다.
- 파이썬 이외에 컴퓨터 내의 다른 시스템에 의해 성능에 상당한 영향을 받을 수 있다.
- 입력값에 따라 실행시간이 달라질 수 있다.
- 성능에 영향을 주는 파라미터의 개수가 두개 이상인 경우도 고려하자.여기서 m과 n 두개의 파라미터로 한 값을 분석할 때 다른 값은 고정시키므로 mn이라는 시간복잡도를 가진다.
for i in range(m): for j in range(n): if a[i] + b[j] ==0: count+=1
공간복잡도
공간복잡도란?
특정한 크기의 입력에 대하여 알고리즘이 얼마나 많은 메모리를 차지하는 지를 의미한다. 언제 프로그램이 요구하는 메모리양 때문에 주어진 문제를 해결할 수 없을지를 대략적으로나마 알고 있어야하기 때문에 공간복잡도에 대한 감 역시 잡아두는 것이 필요하다.
- 파이썬 프로그램의 메모리 사용량을 알아내기 위해,데이터 타입에 따라 각 객체가 요구하는 바이트 수로 가중치를 더한다.
- 프로그램에서 사용하는 객체수를 세고,
Bool 형과 캐시
- Bool형
- bool값을 표현하기 위해 파이썬은 컴퓨터 메모리에서 단 하나의 비트로 표현할 수 있다.
- 그러나 파이썬은 불값을 정수로 표현하여, True와 False를 표현하는데 24바이트를 소비한다.
- 최소 필요한 양에서 192배의 메모리를 사용하는 메모리 낭비를 절약할 수 있도록 두 개의 bool객체를 캐시한다.
- 캐시
- 메모리를 절약하기 위해 파이썬은 어떤 값을 가진 객체의 사본을 하나만 만든다.
- True값을 가진 bool객체 하나와 False값을 가진 bool객체 하나만을 만들어 모든 bool뱐수가 이 두 객체를 참조하도록 한다.
- 전형적으로 파이썬은 프로그래머들이 자주 사용하는 -5에서 256사이의 작은 int값들을 캐시하고, float객체는 캐시하지 않는다.
- 메모리를 절약하기 위해 파이썬은 어떤 값을 가진 객체의 사본을 하나만 만든다.
객체
- 하나의 사용자 객체를 표현하기 위해 필요한 메모리는 최소 수백 바이트이다.
- 파이썬이 기본적으로 소비하는 72바이트 + 인스턴스 변수를 객체에 연결하기 위한 딕셔너리에 280바이트 + 각 인스턴스 변수에 24 바이트 + 인스턴스 변수 자체를 위한 메모리
- 메모리를 추정하는 작업을 복잡하게 만드는 요소(캐시, 함수호출에 따른 동적 처리) 때문에 정확한 측정이 힘들 수 있다.
- 함수 호출에 따른 동적처리란
- 함수를 호출할 때 시스템은 함수에 필요한 메모리를 스택에서 할당하는데, 함수가 호출자로 반환될 때 이 메모리도 함께 반환된다. 때문에 재귀함수에서 큰 객체를 생성하는 것은 위험하다.
- 모든 객체는 자신을 참조하는 변수가 실행되는 동안 보존된다.
- 자신을 참조하는 변수가 사라지면 garbage collection 이라는 시스템 처리를 통해 힙에 반환된다.
- 함수 호출에 따른 동적처리란
- 어찌됐든, 사용자 정의 데이터 타입이 아주 많은 메모리를 사용할 수 있음을 염두해둘 필요가 있다.
자료구조
파이썬의 자료구조는 다음과 같이 나눠볼 수 있다.
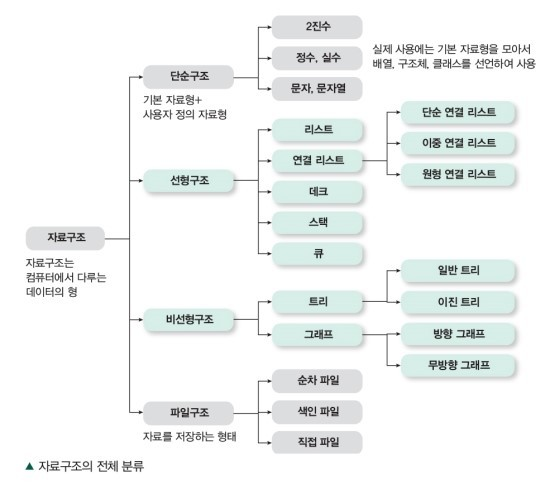
단순구조
정수
- 메모리
- int 객체를 표현하기 위해, 오버헤드에 16바이트와 객체 값 자체를 위해 8바이트, 총 24바이트를 사용한다.
- 오버헤드란?예를 들어 A라는 처리를 단순하게 실행한다면 10초 걸리는데, 안전성을 고려하고 부가적인 B라는 처리를 추가한 결과 처리시간이 15초 걸렸다면, 오버헤드는 5초가 된다. 또한 이 처리 B를 개선해 B'라는 처리를 한 결과, 처리시간이 12초가 되었다면, 이 경우 오버헤드가 3초 단축되었다고 말한다
- 오버헤드(overhead)는 어떤 처리를 하기 위해 들어가는 간접적인 처리 시간 · 메모리 등을 말한다.
- 해당 범위를 벗어나는 정수를 처리하기 위해선 내부적으로 다른 표현법을 사용하는데, 이때는 문자열의 경우와 마찬가지로 정수 길이에 비례해 메모리를 소비한다.
실수
- 메모리
- float객체를 표현하기 위해 오버헤드에 16바이트, 숫자값에 8바이트, 총 24바이트를 소비한다.
문자, 문자열
리스트와 특성이 비슷하지만 문자열은 불변형이다. → 문자열에서 문자를 바꾸는 것은 불가능
- 문자열 객체는 다음 두가지 정보를 담고있다.
- 문자열에 연속적으로 저장된 문자들의 메모리 위치에 대한 참조
- 문자열의 길이
- 문자열 표현이 배열 표현보다 훨씬 간단하다 → 한 문자당 사용하는 공간이 더 적고 더 빨리 접근할 수 있다.
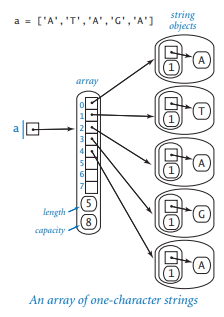
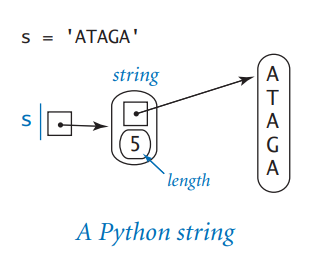
- 시간
- 문자열에 문자를 연결하는 연산은 선형시간, 두 문자열을 연결하는 연산은 생성할 문자열의 길이에 비례하는 시간이 걸린다.
- 이에 비해 배열에선 문자를 추가하는 연산은 평균적으로 상수시간이 걸린다.
- 메모리
- 문자열의 각 문자는 1바이트이며, 그 외에 40바이트의 오버헤드를 가진다.
선형구조
리스트
각 리스트의 요소가 객체로서 메모리에 저장되고, 각 배열의 요소는 해당 객체를 가리키는 구조이다.
- 읽기, 쓰기, 인덱싱, 반복과 같은 연산들을 지원한다.
- 가변 길이 배열 (용량 자동 조절), dynamic array
- 일련의 항목들을 저장하는 데이터 구조로, 두배나 절반으로 배열의 길이를 조절하며 가변 길이 배열이 25%에서 100%사용되도록 보장한다.
- 즉, 마지막에 항목을 추가할 때 배열의 길이를 확인 후, 공간이 있으면 배열 끝에 새 항목을 추가하고, 공간이 없다면 길이가 두배인 배열을 새로 만들어 길이를 두 배로 증가시켜서 새로 리스트를 새로 할당한다. 이전 요소들을 모두 새로 만든 리스트로 옮긴다. ( worst cast: O(n), avg: O(1) )
-
- 단순 append는 상수시간, 길이 조정 시에는 선형시간 소요
-
- 반대로 마지막에서 항목을 제거할 때, 길이가 너무 크면 절반 길이의 배열을 새로만들어 용량을 줄일 수 있다.
- 실제 구현은 정확히 해당 비율로 작동되지 않는다. 배열을 증가시킬 때 2배가 아니라 9/8비율로 용량을 확장시킴으로써 확대 및 축소 연산의 빈도는 많아졌지만 메모리 낭비량을 줄이는 방식으로 작동된다.
- 메모리
- 72바이트의 오버헤드와 , 배열의 각 객체들을 참조하기 위해 각 객체마다 8바이트씩 더 사용한다. 또한 배열이 참조하는 객체에 대한 메모리가 추가적으로 소비된다.
- [0,2,5]에 대해 72bytes + 3_8 bytes= 96bytes + 3_24byte= 168bytes
- 일반적으로 n개의 정수나 실수를 담은 배열은 72 + 32n바이트 이상을 소비한다.
- 72바이트의 오버헤드와 , 배열의 각 객체들을 참조하기 위해 각 객체마다 8바이트씩 더 사용한다. 또한 배열이 참조하는 객체에 대한 메모리가 추가적으로 소비된다.

연결리스트
연결리스트는 메모리 상에 흩어져있는 값들을 None이나 node로 참조한 구조체이다.
- node엔 현재 값에 있는 data 값(key)과 그 다음 값이 저장된 곳의 주소인 link값으로 구성되어 있다.
- ‘to’, ‘be’, ‘or’ 이 있을 때 각 문자열 값들은 key, link에는 다음 노드 객체에 대한 참조를 담는다.
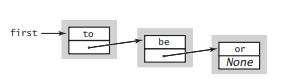
- 연결리스트의 끝에있는 마지막 객체는 None으로 표시한다.
- 실행시간
- 배열이 인덱싱으로 값을 읽는데 상수시간이 걸리는 반면, 연결리스트는 선형시간이 걸린다.
- 이는 값들이 연속적으로 할당되어있지 않기 때문이다.
- 따라서 값을 읽기 위해서는, 가장 앞에 있는 head node를 따라 노드 위치까지 읽어나가야한다.
- 배열이 인덱싱으로 값을 읽는데 상수시간이 걸리는 반면, 연결리스트는 선형시간이 걸린다.
- 특징
- 값을 삽입하거나 제거할 때 상수시간만 소요된다.
- 노드를 삽입할 때 그 전 노드의 링크 값과 삽입하는 노드의 링크 값만 바꿔주면 된다.
- 링크 값을 바꾸는 것은 주소 값을 바꾸는 것이기 때문에 상수시간만 소요된다.
- 연결리스트를 사용하면 메모리 사용량을 걱정하지 않고 다양한 컬렉션을 구현할 수 있으므로 메모리 관리 구현과 관련해 알아두어야하는 구조체이다.
- 값을 삽입하거나 제거할 때 상수시간만 소요된다.
- 한방향 연결 리스트와 양방향 연결 리스트
- 한방향 연결리스트: 한 쪽 방향으로만 갈 수 있는 하나의 링크를 각 노드가 갖고 있는 연결 리스트
- 양방향 연결리스트: 양 쪽으로 갈 수 있는 두개의 링크를 각 노드가 갖고 있는 연결 리스트
스택
후입선출 LIFO정책에 기반한 컬렉션형으로, 나중에 넣은 것을 먼저 꺼내는 방식의 구조이다.
- 메서드
StackqpushpopisEmpty…
- 구현
- 리스트와 연결리스트를 통해 push 와 pop메서드를 구현할 수 있다.
- 리스트의 경우 배열의 크기를 조정해야하므로 모든 연산에 상수시간이 보장되지 않으나, 연결 리스트를 사용하면 최악의 경우에도 일정 메모리 공간만 사용하며 push와 pop메서드를 상수시간으로 실행할 수 있다.
- 그러나 일반적으로는 리스트를 선호한다.
- Node를 구현할 경우, 사용자 정의 데이터 타입에는 상당한 오버헤드가 있기 때문
- 어떤 항목이든 인덱스를 통해 상수시간에 접근할 수 있는 배열의 특징이 특정 연산들을 구현할 때 아주 중요하기 때문

- 응용
- 스택은 컴퓨터 계산에서 아주 중요한 역할을 하며, 표현식 평가, 함수 호출 외 기본적인 작업을 구현하기 위해 컴퓨터 초창기부터 사용되어 왔다.
- 함수 호출과 스택
- 함수를 호출하기 위해 현재 상태를 스택에 푸시한다.
- 함수에서 돌아오기 위해 스택에서 상태를 pop해 모든 변수를 함수 호출 이전 상태로 복원하고
- 함수가 반환한 값은 함수를 호출한 표현식의 값으로 대체한다.
큐
선입선출 FIFO정책에 기반한 컬렉션으로, 먼저 넣은 것을 먼저 꺼내는 구조이다. 음식점에 들어가기 위한 웨이팅 줄을 생각하면 된다.(먼저 기다린 사람 먼저 음식점에 들어감)
- 메서드
QueueenqueuedequeueisEmpty
- 구현
- 마찬가지로 리스트와 연결리스트를 통해 enqueue와 dequeue를 구현할 수 있다.
- 연결리스트의 경우 모든 메서드가 상수시간에 실행되며, 메모리 공간 사용량은 큐 항목수에 선형으로 비례한다.

해시테이블
해시 함수를 통해 키를 빠르게 검색할 수 있는 작은 그룹으로 분할하는 데이터 구조로, 이 구조의 효율성은 해시 함수의 품질에 달려있다.
- 해시함수 hash function (m: 해시테이블 크기, 슬롯의 개수)
- 키를 0과 m-1 사이의 정수인 해시 값으로 대응시키는 함수이다.
- 이 함수를 사용하여 나온 값을 배열 인덱스로 사용해 리스트에 바로 접근할 수 있도록 한다.
- 성능이 좋으려면 해시 함수가 키들을 적절히 분산시켜(인덱스가 겹치지 않도록) 값이 들어가도록 해야한다.
- ex) hash(2017) = 2017 % 10= 7, 7번째 인덱스에 키, 값 추가 / hash(2019) =2019 % 10= 9, 9번째 인덱스에 키, 값 추가 → 여기서 해시함수는 나머지 구하는 연산
- best hash function은 연산속도가 빠르면서 충돌이 발생하지 않는 함수이다.
- 최소 50%이상의 빈 슬롯이 있다면 해시함수의 메서드는 평균적으로 상수시간 내에 연산된다. → 큰 데이터셋에서 많이 활용될 수 있음
- collision resolution method
- 저장할 위치에 다른 아이템이 저장되어 있는 경우 ‘충돌’이 발생했다고 함.
- 이를 해결하는 방법을 collision resolution method라고 하고 이에는 다양한 방법들이 존재한다.
- open addressing
- 충돌할 때 그 주위의 빈칸을 찾아서 값을 넣는 방식
- linear probing탐색하고 삽입하는데 시간이 많이 걸릴 수 있음.
- 한칸씩 밑으로 내려가면서 빈칸을 찾는 방식,
- quadratic probingk+1^2, k+2^2 …
- 현재 위치에 순차적 수의 제곱수를 더한 값의 위치의 빈칸을 찾아보는 방식.
- double hashing
- hash함수를 두 개 사용하는 방식
- chaining
- 하나의 슬롯에 여러개의 값 저장 ← 각 슬롯에 한방향 연결리스트를 가리키도록 함으로써 구현
- 딕셔너리 데이터타입
- 딕셔너리 객체를 만들고 key, value값을 반환하는데 상수 시간이 소요된다.
- 내부에 해시테이블을 사용하므로 정렬 속성을 이용한 연산은 지원하지 않는다.
비선형구조
트리
부모와 자식노드가 있는 데이터 구조로, 자식이 하나밖에 없는 경우는 연결리스트와 같다고 볼 수 있다.
최대 두개의 자식노드까지 허용하는 트리를 이진트리 binary tree라고 한다.
- 노드 node, 맨 위의 노드 root node, 맨 마지막 노드 leaf node
- 링크 link, 엣지 edge : 노드를 연결하는 선
- 레벨 level: 트리의 계층 == 높이
- 경로 path: v → w node까지 가는데 거쳐가는 노드들, 경로의 길이 path length
- 아래와 같이 왼쪽 노드와 오른쪽 노드에 대한 링크를 통해 트리를 나타낼 수 있다.

- 새로운 노드를 만들고 링크 하나만 변경함으로써 새 노드를 추가할 수 있다. 또한 주어진 키를 검색하거나 새로운 키를 가진 노드를 추가할 위치를 쉽게 찾아낼 수 있다.
- 검색한 키와 노드의 키를 비교하여 작으면 왼쪽 하위트리로, 크면 오른쪽 하위트리를 재귀적으로 검색한다.
- 일부 노드에만 접근하기 때문에 이진트리에서 put과 get은 트리의 모양에 따라 로그시간에 처리 될 수 있다.
- 최선의 경우: 트리가 완전히 균형잡혀 있는 경우(모든 노드의 자식노드가 두 개씩) → 루트에서 각 단말 노드까지의 거리가 log n임
- 일반적인 경우: 무작위 순으로 키를 삽입해도 검색시간은 로그에 비례 → 거의 절반의 노드로 나누며 검색하기 때문
- 최악의 경우: 각 노드에 Null링크가 하나씩 존재해 한방향의 링크로 이뤄져 있는 경우
그래프
개체들간의 관계를 나타내는 데이터 구조이다.
- G(Vertex, Edge)
- 일련의 꼭짓점과 변으로 구성되는데, 각각의 변은 두 꼭짓점 간의 연결을 나타낸다. 연결된 두 꼭짓점은 이웃이고 한 꼭짓점의 차수는 자신의 이웃 수이다.
- 그래프 표현법
- 인접 행렬 adjacent matrix, 이어져있으면 1, 이어져있지 않으면 0
- 단점: edge가 없을 경우 행렬의 많은 부분이 0으로 채워지기 때문에 메모리 낭비
- 메모리: nxn의 행렬이므로 O(n^2)
- 인접해있는지 확인하는 실행시간: O(1)
- 특정 노드에 인접한 모든 노드에 대한 실행시간: O(n)
- 새 엣지 삽입하는 실행시간: O(1)
- 엣지 삭제하는 실행시간: O(1)
- → 모든 노드 확인하는 경우 제외하고 모두 상수시간
- 인접 리스트 adjacency list로 연결리스트로 표현 가능
- 메모리: 노드 n, 엣지 m 일 때 n개의 노드에 m개의 엣지가 연결되기 때문에 O(n+m)
- 인접해있는지 확인하는 실행시간: 최악의 경우, O(n) ← 노드를 찾을 때 노드에 많이 연결되어있을 때 해당 노드들을 모두 확인해야하기 때문
- 특정 노드에 인접한 모든 노드에 대한 실행시간: O(인접노드 수) → 인접행렬과 달리 인접리스트에는 인접한 노드들만 연결되어있기 때문에 인접행렬보다 실행시간이 덜 소요됨
- 새 엣지 삽입하는 실행시간: O(1)
- 엣지 삭제하는 실행시간: O(n)
- → 메모리 측면에선 인접행렬보다 효율적이지만, 엣지의 개수가 많은 dense한 데이터라면 인접행렬도 괜찮을 수 있다.
- 인접 행렬 adjacent matrix, 이어져있으면 1, 이어져있지 않으면 0
Reference
- Data Structures with Python 강의
- Introduction to programming in python, Robert Sedgewick
'CS' 카테고리의 다른 글
| 네트워크 프로토콜 (0) | 2022.08.30 |
|---|---|
| 파이썬 - 객체지향 프로그래밍 (0) | 2022.08.25 |