BigQuery란?
서버리스(Serverless) 대규모 데이터 웨어하우스. "서버리스"라는 말은 사용자가 서버를 사고 관리할 필요 없이, 그냥 데이터를 넣고 SQL로 질문만 던지면 된다는 뜻
BQ 핵심 특징
① 초고속 성능 (분산 컴퓨팅)
빅쿼리는 수천 대의 컴퓨터가 동시에 작업하는 Dremel이라는 엔진을 사용하여 테라바이트(TB) 단위의 데이터도 단 몇 초 만에, 페타바이트(PB) 단위도 몇 분 안에 분석함.
② 저장소와 연산의 분리 (Separation of Storage and Compute)
데이터를 저장하는 곳과 계산하는 엔진이 완전히 떨어져 있어서, 각각 필요한 만큼만 확장하고 비용을 낼 수 있음.
따라서, 데이터를 많이 저장한다고 해서 분석 엔진 비용이 올라가지 않고
분석을 많이 한다고 해서 저장 공간을 늘릴 필요가 없음.
③ 열 기반 저장 방식 (Columnar Storage)
일반적인 DB는 데이터를 가로(Row)로 읽지만, 빅쿼리는 세로(Column)로 읽음.
따라서 만약 100개의 컬럼 중 '매출' 컬럼만 필요하다면, 나머지 99개는 쳐다보지도 않고 '매출' 열만 읽기 때문에 속도가 압도적으로 빠르고 비용도 절감됨.
BQ 장단점
| 장점 (Pros) | 단점 (Cons) |
| 관리 제로: 인프라 설정이 전혀 필요 없음 | 비용 통제 주의: 쿼리 한 번에 수백 GB를 읽으면 비용이 순식간에 늘어남 |
| 확장성: 데이터가 늘어나도 성능 저하가 거의 없음 | OLTP 부적합: 한 줄씩 자주 수정/삭제하는 작업에는 매우 느리고 비쌈 |
| 친숙함: 표준 SQL을 그대로 사용 | 구글 종속성: 구글 클라우드 환경에 최적화되어 있음 |
Table Type in BQ
| 테이블 유형 | 데이터 저장 위치 | 주요 특징 | 장점 | 단점 |
| 표준 테이블 (Standard) |
BigQuery 내부 | 모든 데이터를 직접 관리 (Native) | 최고 성능, 파티셔닝/클러스터링 풀지원 | 저장 비용 발생, 데이터 로드 과정 필요 |
| 외부 테이블 (External) |
Cloud Storage, Drive 등 외부 | 원본 소스를 건드리지 않고 연결만 함 | 데이터 이동 없음, 실시간 파일 분석 가능 | 표준 대비 느린 속도, 기능 활용 제한 |
| 일반 뷰 (Logical View) |
없음 (쿼리 저장) : 실제 데이터를 가지고 있지 않은 가상 테이블 |
실행 시마다 원본 테이블을 참조함 | 논리적 구조 단순화, 보안(컬럼 제한)에 유용 | 매번 계산하므로 대규모 데이터에선 비용 발생 |
| 구체화된 뷰 (Materialized View) |
BigQuery 내부 : 실제 데이터를 가지고 있는 뷰 |
쿼리 결과를 실제로 물리 저장함 | 압도적 집계 속도, 자동 쿼리 재작성 기능 | 저장 비용 발생, 지원되는 SQL 문법에 제한 있음 |
❓ 표준 테이블과 구체화된 뷰의 차이는?
표준 테이블과 구체화된 뷰(Materialized View, MV)는 둘 다 데이터를 물리적으로 저장한다는 공통점이 있지만, "누가 관리하고 어떻게 업데이트하느냐"에서 결정적인 차이가 납니다.
상황별로 언제 무엇을 써야 할지 깔끔하게 정리해 드릴게요.
1. 표준 테이블 (Standard Table)
데이터의 '원본' 또는 '최종 결과물'을 저장할 때 사용합니다.
- 사용 시점:
- 데이터를 외부에서 처음 불러올 때 (Raw Data 적재).
- 복잡한 ETL(추출, 변형, 로드) 과정을 거쳐 완성된 최종 데이터 세트를 만들 때.
- 데이터의 모든 세부 사항(Raw Level)을 보존해야 할 때.
- 특징:
- 수동 관리: 데이터 업데이트를 위해 INSERT, UPDATE, MERGE 쿼리를 직접 실행해야 합니다.
- 자유도: 모든 SQL 문법과 기능을 제약 없이 사용할 수 있습니다.
2. 구체화된 뷰 (Materialized View)
자주 반복되는 '집계 작업(합계, 평균 등)'을 자동화하고 가속화할 때 사용합니다.
- 사용 시점:
- 수십억 건의 데이터를 SUM, COUNT, AVG 등으로 미리 요약해두고 싶을 때.
- 실시간에 가까운 집계가 필요할 때 (원본이 바뀌면 MV도 자동으로 업데이트됨).
- 특정 쿼리가 너무 자주 실행되어 비용이 많이 나올 때.
- 특징:
- 자동 관리: 원본 테이블에 새 데이터가 들어오면 빅쿼리가 배경에서 자동으로 MV를 업데이트합니다.
- 스마트 튜닝: 사용자가 원본 테이블을 조회하더라도, 빅쿼리가 판단해서 "어? MV를 읽는 게 더 빠르고 싸겠네?" 하면 자동으로 쿼리 경로를 MV로 변경합니다.
3. 핵심 비교: 한눈에 고르기
| 선택 기준 | 표준 테이블 (Standard) | 구체화된 뷰 (MV) |
| 핵심 용도 | 데이터의 영구 저장 및 가공 | 대규모 집계 성능 최적화 |
| 데이터 업데이트 | 직접 쿼리 실행 (DML) | 원본 변경 시 자동 업데이트 |
| 쿼리 복잡도 | 제한 없음 (JOIN, Subquery 등) | 집계 함수 위주 (JOIN 등 일부 제한 있음) |
| 최적화 대상 | 모든 형태의 쿼리 | 자주 사용되는 집계(Aggregation) 쿼리 |
4. 실전 예시
상황 A: "매일 밤 매출 리포트를 생성해야 합니다."
- 선택: 표준 테이블
- 이유: 하루 한 번만 생성하면 되고, 여러 테이블을 복잡하게 조인(Join)하여 비즈니스 로직을 녹여야 하므로 표준 테이블이 적합합니다.
상황 B: "대시보드에서 1초마다 실시간 판매 합계를 보여줘야 합니다."
- 선택: 구체화된 뷰 (MV)
- 이유: 데이터가 들어올 때마다 자동으로 합계를 계산해주며, 대시보드 쿼리 속도를 비약적으로 높여주기 때문입니다.
<그 외 특수 유형 테이블>
- 임시 테이블 (Temporary): 쿼리 실행 시 결과가 캐시되는 테이블로, 24시간 후 자동 삭제됨
- 테이블 스냅샷 (Snapshot): 특정 시점의 테이블 상태를 '사진' 찍듯 보관하며, 원본과 차이가 나는 데이터에 대해서만 비용을 청구하여 효율적임
- 테이블 복제본 (Clone): 스냅샷과 비슷하지만, 복제된 테이블에서 직접 데이터를 수정할 수 있다는 차이가 있음
Partitioning & Clustering in BQ
Partitioning
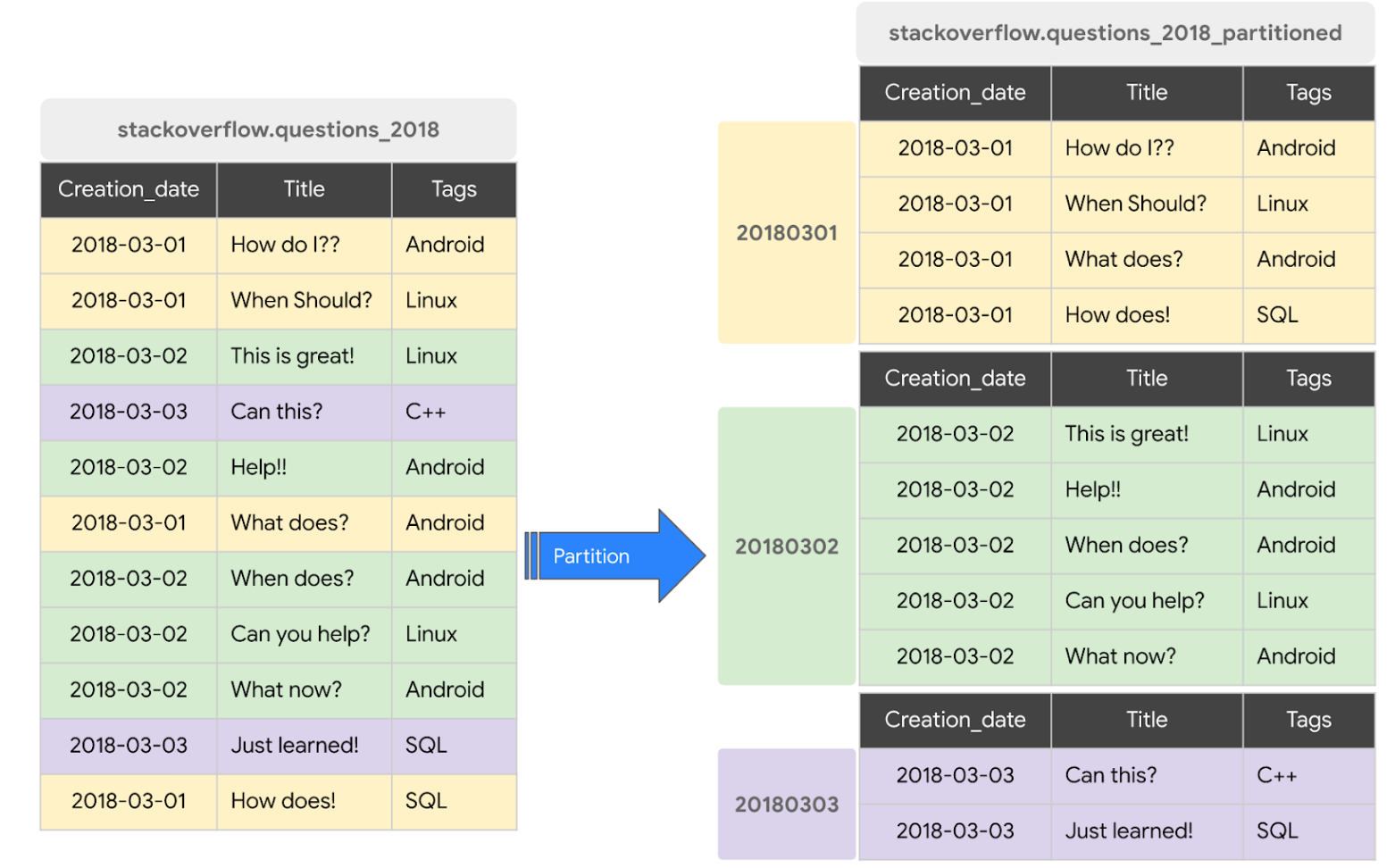
데이터를 특정 기준(주로 날짜)에 따라 물리적인 작은 단위(파티션)로 쪼개는 것
- 원리:
1. 특정 컬럼에 따라 물리적인 파티션 생성
2. WHERE 절에 파티션 컬럼을 사용하면, 조건에 해당하지 않는 파티션은 아예 읽지도 않음 (= Partition Pruning) - 기준: 주로 날짜/시간(수집 시간, 특정 날짜 컬럼)이나 정수 범위를 사용함
- 장점: 읽는 데이터 양이 줄어드므로 비용 절감과 속도 향상이 동시에 일어남
<Code in Bigquery>
CREATE TABLE `my_project.my_dataset.events_partitioned`
(
event_date DATE,
user_id STRING,
event_name STRING,
event_timestamp TIMESTAMP
)
PARTITION BY event_date;
Clustering
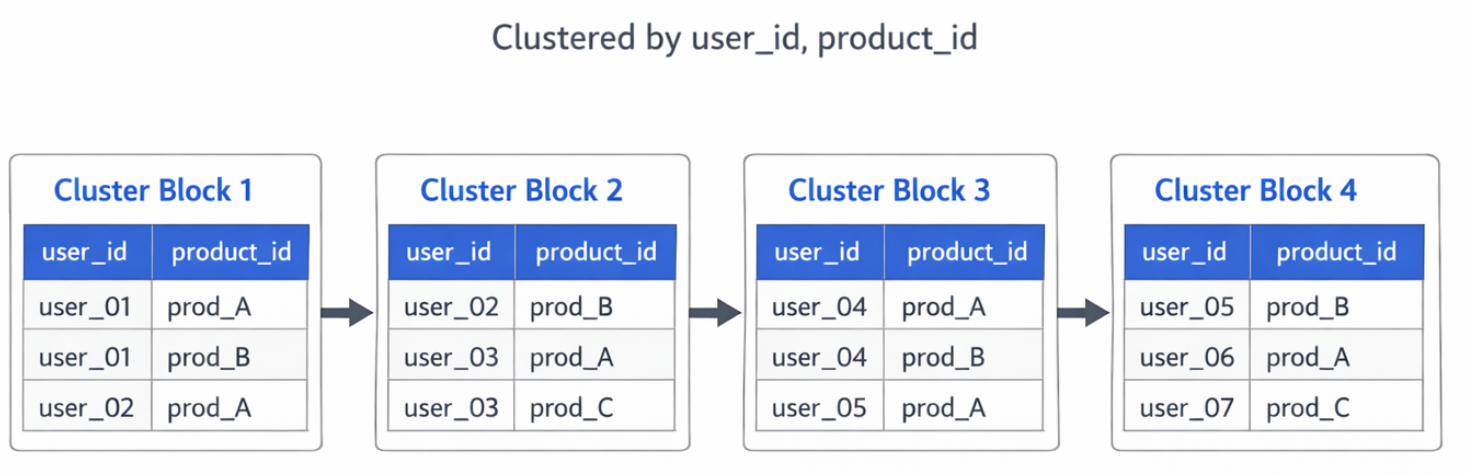
파티션 내부에 저장된 데이터를 특정 컬럼의 값을 기준으로 정렬하여 보관하는 것
- 원리:
1. 정렬 및 블록화 : 테이블 생성 시 CLUSTER BY user_id, product_id라고 설정하면, 빅쿼리는 데이터를 user_id, product_id 순서대로 정렬. 그리고 정렬된 상태를 유지하며 물리적 블록에 나눠 담음.
2. 메타데이터 생성 : 각 블록마다 어떤 값이 들어있는지 최솟값과 최댓값 정보를 별도의 메타데이터 저장소에 기록.
3. 블록 건너뛰기 : 쿼리가 들어왔을 때 메타데이터 기록을 기반으로, 조건에 해당하는 블록만 읽음으로써 I/O 비용을 획기적으로 줄임.
EX ) user_07은 Block4에만 있겠군! Block4 만 read - 기준: 거의 모든 타입의 컬럼을 기준으로 설정 가능하며, 주로 Cardinality가 높은 ID, 이름 등을 기준으로 사용.
- 장점: Cardinality, 고유값의 개수 가 높은 컬럼(예: 사용자 ID, 상품 코드)을 조건으로 쓸 때 유리함.
BigQuery에서 데이터가 추가되어 정렬이 깨지면, 구글이 백그라운드에서 알아서 다시 정렬해주며, 해당 작업에 대해서는 추가 비용이 청구되지 않음.
<Code in Bigquery>
CREATE TABLE `my_project.my_dataset.events_clustered`
(
event_date DATE,
user_id STRING,
event_name STRING,
country STRING
)
CLUSTER BY user_id, event_name; // user, event 기준으로 정렬하여 저장
정리하면..
| 구분 | 파티셔닝 (Partitioning) | 클러스터링 (Clustering) |
| 작동 방식 | 데이터를 물리적 큰 덩어리로 나눔 | 데이터 내 내용을 특정 순서로 정렬 |
| 비용 관리 | 쿼리 전 비용 예측 가능 | 쿼리 실행 전에는 정확한 절감량 알 수 없음 |
| 컬럼 제한 | 단일 컬럼만 가능 | 최대 4개 컬럼까지 조합 가능 |
| 권장 기준 | 날짜, 시간, 숫자 범위 (저장 용도) | ID, 이름, 카테고리 등 (필터링 용도) |
| 언제 사용? | - 데이터 사이즈가 1GB 보단 클 때 - 테이블이 크지만 parition 은 적게 필요할 때 - 비용을 예측할 수 있어야 할 때 |
- Partition 개수가 4,000개보다 많을 때 (Partition 개수는 4000개로 제한되어있음) - Partition 별 데이터 양이 적을 때 (각 1GB 미만일 때) - Parition 이 자주 바뀔 때 (매 분 업데이트 등..) |
| Best Practice | 1. 먼저 날짜로 파티셔닝을 합니다. (예: event_date) -> "최근 7일 데이터만 볼래!" 할 때 비용이 획기적으로 줄어듬 2. 그 안에서 자주 검색 조건으로 쓰이는 ID나 카테고리로 클러스터링을 합니다. (예: user_id, event_type) -> "그 7일치 중에서 'A' 유저의 기록만 찾아줘!" 할 때 속도가 매우 빨라짐 |
|
BQ 사용 팁
1. 읽기량 줄이기
빅쿼리는 스캔한 데이터 양만큼 돈을 받기 때문에 가장 먼저 해야 할 일은 데이터를 적게 읽는 것임.
- SELECT * 금지: 필요한 컬럼만 명시
- 파티션 필터 사용: WHERE 절에서 파티셔닝된 컬럼(주로 날짜)을 사용하여 필요한 날짜의 데이터만 읽도록 제한
- 미리 보기(Preview) 활용: 데이터 내용을 확인하고 싶을 때는 쿼리를 날리지 말고 '미리 보기' 탭 사용. (미리보기는 비용 X)
2. 집계 성능 향상
- 구체화된 뷰(Materialized View) 사용: 자주 반복되는 집계(Sum, Count 등)는 미리 계산된 MV를 사용.
- 근사 함수(Approximate Functions) 활용: 정확한 수치가 아닌 "대략적인 추세"가 중요하다면 COUNT(DISTINCT) 대신 속도는 훨씬 빠르고 비용은 훨씬 저렴한 APPROX_COUNT_DISTINCT를 사용.
3. 테이블 & 쿼리 구조
- ORDER BY는 마지막에: 정렬은 연산 비용이 매우 높기 때문에 꼭 필요한 경우가 아니라면 가장 바깥쪽 쿼리에서 마지막에 한 번만 수행.
- 중복 계산 방지: 똑같은 서브쿼리가 여러 번 쓰인다면 임시 테이블이나 CTE를 활용해 한 번만 계산하도록 하기.
- Overshading table 사용 지양 : Oversharding이란, 데이터를 너무 잘게 쪼개서 수천 개 이상의 작은 테이블로 나누어 관리하는 테이블로, 해당 테이블은 메타데이터 과부하로 인한 쿼리 성능 저하 & 쿼리 작성 복잡함 & 비용 관리에 있어서 한계가 있음.
4. 조인 최적화
- 큰 테이블을 먼저: JOIN을 할 때는 가장 큰 테이블을 왼쪽에 배치. 빅쿼리는 왼쪽 테이블을 기준으로 오른쪽 테이블을 분산시켜 조인하기 때문.
- 조인 전 필터링: 두 테이블을 합치기 전에 WHERE 절로 데이터 크기를 먼저 줄이기.
- 클러스터링 활용: 자주 조인되는 키(예: user_id)가 클러스터링되어 있다면 검색 성능이 비약적으로 향상.
'Data > 데이터 엔지니어링' 카테고리의 다른 글
| [dbt] dbt는 무엇이고, 언제 활용될까? (0) | 2026.02.17 |
|---|---|
| OLAP & Data Warehouse (0) | 2026.02.08 |
| ELT vs ETL 언제 사용하면 좋을까? (0) | 2026.02.02 |
| [Kestra] Workflow Orchestration / Kestra 알아보기 (0) | 2026.01.30 |
| [Docker] Docker + port & network 이해하기 (0) | 2026.01.26 |