파이토치로 배우는 자연어처리 책을 참고하여 작성하였습니다.

본 포스팅은 파이토치로 배우는 자연어 처리 책을 공부하며 따라 작성해본 코드 중에서 좀 더 자세한 설명이 필요하거나 코드에 대해 이해한 부분을 정리해보고자 작성하였다.
▶ 분석 개요
이번 포스팅에서 다뤄볼 데이터셋은 18개 국적의 성씨 10000개를 모은 성씨 데이터 셋으로 데이터 불균형 등의 문제등이 해결되어 이미 전처리가 완료된 데이터를 사용한다. 모델은 다층 퍼셉트론과 CNN을 사용하는데 본 포스팅에선 CNN을 사용한 예제를 풀어보고자 한다.
모델링의 대략적인 진행 과정은 다음과 같다.
토큰들을 정수로 매핑하기 위한 어휘사전을 구축하고 정수로 매핑된 토큰들을 원핫벡터 행렬로 수치화한다. CNN 모델을 구축한 후 학습 및 검증과정을 수행한다. test 데이터에 대한 성능 평가 후 모델에 데이터를 넣었을 때 적합한 국적이 나오도록 하는 코드까지 작성하며 마무리한다.
본 포스팅에는 설명이나 정리가 필요한 코드에 대해서만 캡처 해왔기 때문에 일부 코드는 생략되어있다. 모든 코드를 보고싶다면 이 링크에서 찾아볼 수 있다.
▶ 분석 코드
먼저 모델 구축하기 전 사전 단계이다. 먼저 vocabulary 사전을 구축하는 부분부터 살펴보자
▷ Vocabulary class:
어휘사전을 구축하고 토큰들을 정수로 매핑하기 위한 클래스이다.
- __init__(token_to_idx= None, add_unk= True, unk_token='<UNK>'): 토큰에 대한 인덱스와 토큰 정보를 담은 딕셔너리를 만든다.
- to_serializable(): 토큰- 인덱스가 매핑되어 있는 딕셔너리와 unk토큰을 추가할지 지정하는 플래그인 add_unk, unk_token이 담겨있도록 딕셔너리를 생성한다.
- from_serializable(cls, contents): Vocablulary class를 매개변수로 받아들여 위의 직렬화된 딕셔너리에서 vocabulary 객체를 만든다.
- add_token(token): 토큰을 기반으로 매핑 딕셔너리를 업데이트하는 함수로 __init__에서 호출되어 딕셔너리를 만드는데 사용된다.
- add_many(tokens): 토큰 리스트들을 vocabulary에 추가한다.
- lookup_token(token): 입력 받은 토큰에 해당하는 인덱스를 추출한다. 토큰이 없으면 UNK인덱스를 반환한다.
- lookup_index(index): 인덱스에 해당하는토큰을 반환한다.
- __str__: vocabulary의 크기 반환
- __len__: 토큰=인덱스 매핑 딕셔너리의 크기 반환
▷ SurnameVectorizer class:
위의 Vocabulary클래스를 사용해 어휘사전을 만든다. 또한 vectorizer를 만들어 토큰들을 정수로 바꾸는 클래스이다.
- __init__(surname_vocab, nationality_vocab, max_surname_length): 성씨를 정수에 매핑하기 위해 사용되는 surname_vocab vocabulary 객체, 국적을 정수에 매핑하기 위해 사용되는 nationality_vocab vacabulary객체, 가장 긴 성씨 길이를 나타내는 max_surname_length를 클래스 변수로 선언한다.
- vectorize(surname): 성씨에 대한 원핫 벡터 행렬을 만든다. 여기서 행렬의 각 열들에 각각의 성씨에 대한 원핫 벡터표현이 들어가 다음과 같은 행렬의 모습을 띨 것이다.

그림2. 성씨 원핫벡터 행렬 예시
- from_dataframe(cls, surname_df): 제공받은 데이터프레임에서 입력으로 받아 vectorizer객체를 만든다. 먼저 surname_vocab과 nationality_vocab 사전에 토큰들을 추가하여 vocabulary를 구축하고 해당 어휘사전들과 성씨 중 가장 긴 성씨의 길이를 반환한다.
- from_serializable(cls, contents): 직렬화된 vocab들을 vocabulary객체로 만들고 최대 성씨 길이와 함께 반환한다.
- to_serializable(): vacab들을 직렬화가능한 형태로 만들어준다.
이제 위의 클래스와 함수들을 활용하여 Bert의 데이터 셋을 생성한다.
▷ SurnameDataset class:
Dataset 모듈 상속한 클래스

- __init__(surname_df, vectorizer): 데이터와 vectorizer를 받아 클래스내 변수에 선언하고 데이터를 train, val, test로 나눠준다. 그리고 국적의 빈도에 따라 클래스 가중치를 설정해준다.

- load_dataset_and_make_vectorizer(cls, surname_csv): surname 데이터에서 train 데이터만 추출하여 train 데이터에 대한 vectorizer 객체를 만든다.
- load_dataset_and_load_vectorizer(cls, surname_csv, vectorizer_filepath): vectorizer가 이미 존재할 때에는 vectorizer가 저장된 파일 위치에서 load_vectorizer_only함수를 사용해 불러와 사용한다.
- load_vectorizer_only(vectorizer_filepath): json형태로 직렬화된 vectorizer를 vocabulary 객체로 불러온다.

- save_vectorizer(vectorizer_filepath): vectorizer를 저장하고 싶을 때 json형태로 저장한다.
- get_vectorizer(): vectorizer 객체를 반환한다.
- set_split(split= "train"): split매개변수로 train, test, val 중 하나를 선택할 수 있고 해당 인덱스에 맞게 데이터를 분할하여 분할된 데이터와 그 크기를 반환한다.
- __len__: target의 크기를 반환한다.
- __getitem__(index): index를 넣으면 그 인덱스에 해당하는 성씨의 원핫 벡터 행렬과 국적 인덱스를 반환한다.

- get_num_batches(batch_size): 배치크기를 입력하면 데이터 셋으로 만들 수 있는 배치의 개수를 반환한다.
- generate_batches(dataset, batch_size, shuffle=True, drop_last=True, device="cpu"): dataset과 배치 사이즈를 넣어주면 데이터 포인트들을 미니배치로 모아준다.
CNN모델을 구축한다.
▷ SurnameClassifier(nn.Module):
nn모듈을 상속한 CNN 분류기를 만드는 클래스이다.

- __init__(initial_num_channels, num_classes, num_channels): 입력 벡터 채널 크기, 출력 예측 벡터 크기, 신경망 전체에서 사용할 채널의 크기를 입력값으로 넣어 사용한다. 해당 함수에서 Sequential함수를 사용해 모델 층을 쌓아 주었다. 채널 수는 모든 층에서 동일하게 출력되도록 설정되었다. 자연어처리에 적합한 1차원 합성곱과 ELU 비선형 층을 한칸씩 쌓아주었다. 그리고 마지막엔 예측벡터를 생성할 수 있도록 선형층을 넣어줬다.
ELU
합성곱 층 사이에 사용하기 좋은 ReLU기반 비선형 함수이다.
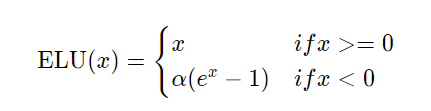
위 공식과 같이 x가 양수이면 그대로 x를, 음수이면 알파에 e^x-1의 값을 도출한다. 알파 값이 크면 클수록 도출되는 값이 더욱 작은 음수값을 가진다. 위 공식을 그래프로 그려보면 다음과 같다.
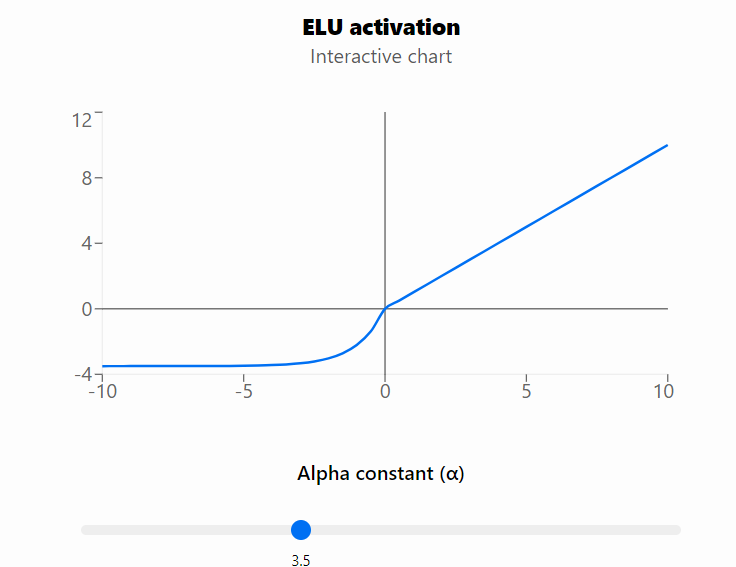
알파가 3.5일때의 그래프이다. 알파가 이보다 더 작아지면 0 이하의 그래프가 0쪽으로 더 올라온 형상을 보인다.
ELU 는 ReLU보다 일반화 성능이 우수하고 완전 연속, 미분가능하다는 장점이 있다. 또한 죽은 렐루 문제도 해결한 함수이지만, 음수 입력값에 대한 비선형성으로 인해 계산속도가 느리다는 단점이 있다.

- forward(x_surname, apply_softmax=False): 모델을 정방향 학습시키는 부분이다. 입력 값을 모델에 넣어 산출한 예측 벡터를 반환한다.
▷ 학습 및 예측
이 부분까지 적합한 데이터 셋을 생성하고 모델을 구축하는 클래스에 대해서 설명했다. 이제 이 데이터와 모델을 가지고 train data를 대상으로 학습한다.
모델 훈련 상태를 업데이트 하는 update_train_state 함수를 선언하고 훈련 파라미터를 다음과 같이 설정한다.
seed=1337,
learning_rate=0.001,
batch_size=128,
num_epochs=100,
early_stopping_criteria=5,
dropout_p=0.1
훈련에 필요한 준비를 마치고 훈련을 수행하고 val 데이터 셋을 통한 검증, test 데이터에 대한 예측을 수행한다.

손실함수는 다중 분류에 사용되는 crossentropyloss로, 가중치는 SurnameDataset의 __init__에서 설정한 가중치를 사용한다. 아담 옵티마이저를 사용하였다.
learning rate를 조절하는 옵티마이저 스케줄러로는 ReduceLROnPlateau를 사용하여 성능 향상이 없을 때 learning rate를 감소시키도록 했다. metric이 향상되지 않을 땐 1번만 참고 그 이후엔 learning rate가 감소할 것이다. (이외에 옵티마이저 스케줄러를 보고 싶다면 이 링크를 참고하자)

위와 같은 방식으로 train 데이터를 통한 학습과 val 데이터에 대한 검증을 수행한 모델로 test 데이터에 대한 정확도를 구하면 정확도는 56.05가 나온다. 같은 데이터에 대해 다층 퍼셉트론 모델의 정확도보다는 높게 나온것을 볼 수 있다.
모델을 통해 새로운 데이터를 넣어 예측하는 코드도 참고하자. 아래 코드는 분류하고픈 성씨를 입력하면 해당 성씨가 어느 국적의 성씨일지 가장 높은 가능성을 가진 국적 순으로 보여준다.

본 포스팅을 통해 파이토치를 활용한 딥러닝 모델 구축에 대한 전반적인 모델링 과정을 정리해보았다. 사실 코드 자체를 처음 봤을 때는 아무래도 풀어서 써져있는 코드보다는 해석하기 어려울 수 있다. 그러나 하나하나씩 뜯어보고 이해하려 하다보면 조금씩 모델링 과정이 이해되기 시작한다. 앞으로도 해당 코드를 활용해 반복적으로 써보면 추후 스스로 딥러닝 코드를 작성할 때에도 도움이 되지 않을까 한다.
'Data > 자연어처리' 카테고리의 다른 글
| [Pytorch] 임베딩 (2) / GloVe임베딩 + CNN 을 활용한 뉴스 카테고리 분류기 구현 (0) | 2021.07.29 |
|---|---|
| 임베딩 (1) / 임베딩 개념 (1) | 2021.07.28 |
| 자연어 처리를 위한 피드포워드 신경망(2)/ 합성곱 신경망, 파이토치 구현 (2) | 2021.07.22 |
| 자연어 처리를 위한 피드 포워드 신경망(1)/ 다층 퍼셉트론, 파이토치 구현 (0) | 2021.07.22 |
| 텍스트를 수치화시키는 방식 4가지 (0) | 2021.07.15 |