fpr, tpr, fnr, tpr은 roc-curve, f1-score등을 산출해내는 지표로, classification문제에서 모델의 분류 정확도를 평가하기 위해 사용된다. 그렇기 때문에 분류모델을 구축하기 위해선 꼭 짚어두고 가야하는 개념이다.
몇 번을 보고, 배운 개념이지만 자꾸 헷갈리고 찾아보게되어 이 기회에 완벽히 숙지하고 넘어가려한다.
▶confusion matrix와 TP,FP,FN,TN
confusion matrix(혼돈행렬)은 단어에서 알 수 있듯이 컴퓨터가 (대표적으로)이진분류 문제를 수행한다고 할때 두개의 클래스를 얼마나 헷갈려하는지를 알 수 있는 지표이다.

열에는 대상의 실제클래스가, 행에는 대상의 예측된 클래스가 위치한다. 각 행렬요소들은 tp, fp, fn, tn으로 구성된다.
두번째 단어인 P와 N을 내가 예측한 값이라고 생각하고 첫번째단어인 T와 F는 내가 예측한 값이 맞았는지 틀렸는지를 알려주는 값이라고 생각하면 된다. 정리하면 다음과 같다.
- TP (True Positive): 내가 positive라고 예측한 값이 맞음-> 실제로 positive인 값을 positive로 잘 예측함.
- FP (False Positive): 내가 positive라고 예측한 값이 틀림-> 실제론 negative인 값을 positive라고 잘못 예측함.
- TN (True Negative): 내가 negative라고 예측한 값이 맞음-> 실제로 negative인 값을 negative로 잘 예측함.
- FN (False Negative): 내가 negative라고 예측한 값이 틀림-> 실제로 positive인 값을 negative라고 잘못 예측함.
예시)
뉴스기사 100문장을 가짜뉴스기사와 진짜뉴스기사로 분류하는 분류모델을 만들었다. 분류모델에 대한 confusion matrix는 다음과 같다.

- TP: 실제로 진짜뉴스인 기사를 진짜뉴스라고 70번 잘 예측함.
- FP: 실제로 가짜뉴스인 기사를 진짜뉴스라고 10번 잘못 예측함.
- TN: 실제로 가짜뉴스인 기사를 가짜뉴스라고 15번 잘 예측함.
- FN: 실제로 진짜뉴스인 기사를 가짜뉴스라고 5번 잘못 예측함.
▶TPR, FPR, FNR, TNR
이 지표들은 confusion matrix를 측정하는 값들로 실제 값에 대한 각 지표들의 비율을 나타낸다.
- TPR (True Positive Rate): TP/ actual positive
- FPR (False Positive Rate): FP/ actual negative
- TNR (True Negative Rate): TN/ actual negative
- FNR (False Negative Rate): FN/ actual positive
예시)
위의 예시에 대한 각 지표들의 비율을 구해보자.
- TPR: 70 / (70+5) = 93.3%
- FPR: 10 / (10+15) = 40%
- TNR: 15 / (10+15) = 60%
- FNR: 5 / (70+5) = 7%
TPR와 TNR이 높을수록 분류기의 성능은 좋은 것이라고 볼 수 있다. 이 비율들로 미뤄봤을 때, 가짜뉴스 진짜뉴스 분류기의 성능은 썩 나쁘지 않은 것으로 보인다.
▶ Precision, Recall, F1- score
위에서 설명한 개념들을 통해 분류기의 성능을 평가하는 점수지표를 생성할 수 있다.
- Precision(정밀도): positive라고 예측한 값들에서 실제로 positive인 값들을 positive라고 잘 예측한 값의 비율을 나타낸다.
ex) 검색 정밀도가 높다: 검색엔진에서 뭔가를 검색했을 때, 내가 검색하고자 한 것과 무관한 검색결과가 나오지 않고 내가 검색하고자 한 결과가 정확하게 나온다.

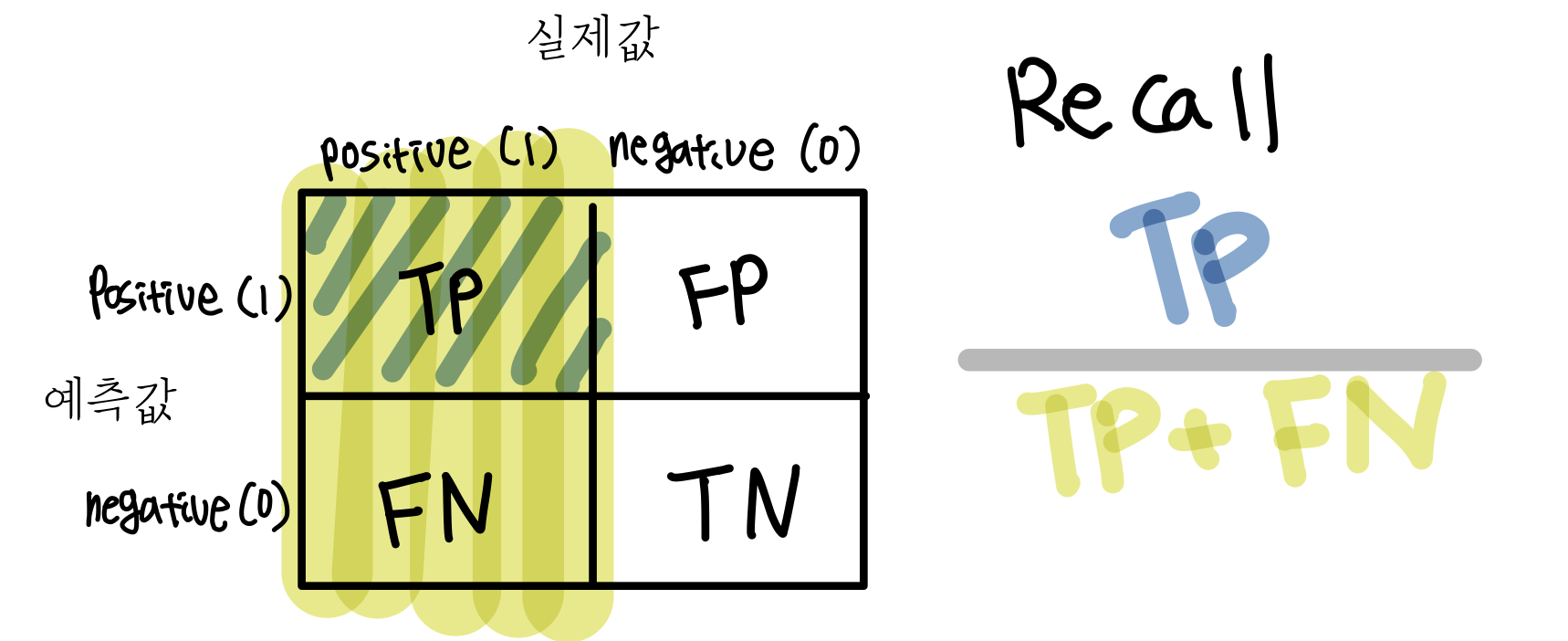
- recall(재현율): 실제로 positive인 값들에서 positive라고 잘 예측한 값의 비율을 나타낸다.
ex) 검색 재현율이 높다: 내가 뭔가를 검색했을때, 반드시 나와야하는 (검색어와 관련있는) 검색결과가 실제로 검색결과에 많이 포함되어있다.
분류 모델은 precision과 recall이 클 수록 더 좋은 모델이라고 할 수 있다.
-f1 score: precision과 recall을 가중평균한 것으로 1이 가장 높은 점수이고 0이 가장 낮은 점수이다.
f1= 2 * (precision * recall) / (precision + recall)
'수학 > 통계학' 카테고리의 다른 글
| p-value란? / p-value 사용 시 주의할 점 (2) | 2022.01.28 |
|---|---|
| 정보이론 / entropy & Cross entropy & KL divergence (0) | 2022.01.20 |
| 의사결정나무_분류모델 (0) | 2020.11.11 |
| 릿지회귀 RidgeRegression (0) | 2020.11.08 |
| 평균- 표본,가중,기하, 조화평균 (0) | 2020.11.08 |