논문명: Attention Is All You Need
저자: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia PolosukhinAshish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
출간지: Conference on Neural Information Processing Systems (NIPS 2017)
발간일: 2017.12.
논문명: Neural Machine Translation by Jointly Learning to Align and Translate
저자:Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio
출간지: ICLR 2015
발간일: 2016.05.

어텐션에 대해 얘기한 Neural Machine Translation by Jointly Learning to Align and Translate논문과 transformer모델을 소개한 Attention Is All You Need 논문에 대해 강의들을 참고해 리뷰한 것을 정리해보았다.
RNN에 attention을 적용한 모델부터 transformer 모델의 원리까지 정리하였다.
▶ seq 2 seq모델의 문제점
seq2seq모델에서는 소스 텍스트들(원문)의 정보를 하나의 고정된 크기의 context vector로 압축하여 표현하고 그 벡터를 디코더에서 풀어 타겟텍스트(번역문)으로 생성한다.
그런데 해당 방식은 소스 텍스트의 길이가 길건 짧건 간에 하나의 벡터로 압축해야하기 때문에 다양한 길이를 표현할 수 없게되고 이는 병목현상을 초래할 수 있다. 이 현상으로 인해 성능이 저하될 수 있다는 문제점이 있다.
이를 해결하기 위해 소스 문장을 하나의 벡터로 압축하지 않고 소스 문장에서의 출력 전부를 매번 입력으로 받아 타겟텍스트로 출력할 수 있다.
▶ seq 2 seq with attention
context vector뿐 만 아니라 인코더에서 소스텍스트의 단어들 각각에서 나오는 출력값들을 참고해 디코더에서 타겟텍스트를 출력할 수 있도록 한다. 이 모델에서는 단어들 각각에서 출력값들이 나오기에 입력으로 들어온 소스텍스트들에서 어떤 단어에 주의 집중해서 출력할 지를 고려할 수 있다는 장점이 있다.
그렇다면 인코더의 소스텍스트들 중 어떤 단어에 집중하는지는 어떻게 도출할 수 있을까?
디코더에서 매번 인코더의 출력 중 어떤 정보가 중요한지 계산하는데 이는 에너지를 이용해 도출할 수 있다. 에너지는 공식1에서 (2)에 해당한다.
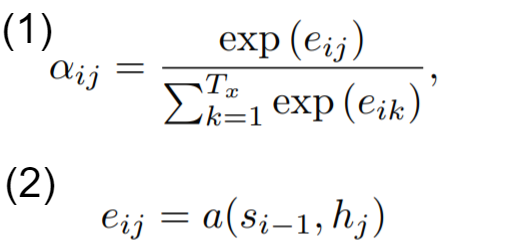
i는 현재 디코더가 처리중인 인덱스를 의미하고 j는 각각의 모든 인코더 출력 인덱스를 의미한다. 따라서 s(i-1)은 이전 순서의 디코더에서 나온 출력값을 의미하고 h(j)는 인코더의 처리중인 인덱스에 대한 모든 출력값을 의미한다.
즉 에너지는 이전 디코더 hidden state의 출력값과 현재 인코더의 모든 출력값들을 비교해서 인코더의 출력값들 중 어떤 값과 가장 연관이 많이 되어있는지를 계산한 값이다.
이 에너지 값을 (1)의 공식을 통해 각 출력에 대한 확률값을 도출 할 수 있다.
(1) 을 통해 얻은 가중치를 인코더의 출력값에 곱하여 모두 더함으로써 weighted sum을 구할 수 있고 이 값에 이전 디코더의 출력값을 반영해주면 현재 위치 i에 해당하는 디코더의 값을 도출 할 수 있다.
이를 그림으로 나타내면 다음과 같다.
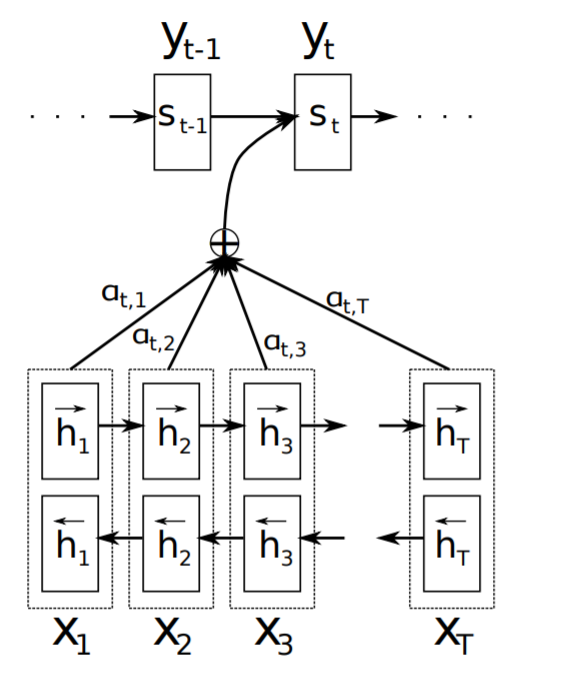
이 과정을 통해 우리는 인코더의 소스텍스트의 x1, x2.. 중에서 어떤 단어가 문장에서 중요한 정보인지를 디코더에 반영해줄 수 있다.
소스텍스트를 번역할 때 소스텍스트의 단어중 어떤 단어가 타겟 텍스트의 번역에 중요한 영향을 끼쳤는지를 다음과 같은 맵을 통해 시각화할 수 있다.

색이 연할 수록 확률이 높은 부분인데 프랑스어에서 accord를 출력할 때 인코더의 영어 텍스트에서 agreement가 큰 영향을 끼쳤음을 볼 수 있다.
여기까지 RNN에 attention을 적용한 모델을 살펴보았다.
해당 모델에선 attention이 decoder가 해석하기에 가장 적합한 가중치를 찾고자 했다.
여기서 생각을 전환해 attention이 디코더가 아니라 아예 input인 값을 가장 잘 표현할 수 있도록 학습하면 자기 자신을 가장 잘 표현하는 좋은 임베딩이 나오지 않을까?라는 생각이 나왔고 이를 구현한 모델이 바로 self- attention 모델이자 Transformer 모델의 기본 아이디어이다.
▶ Transformer
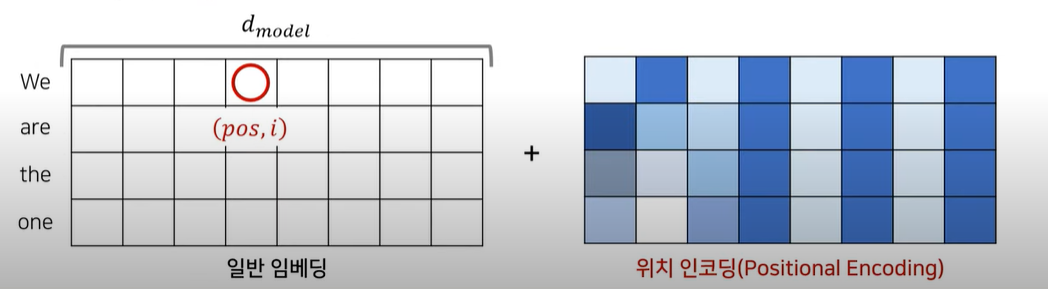
이 모델에서는 RNN을 인코더와 디코더에서 제거하여 어텐션만을 사용하여 학습을 수행한다. 해당 모델은 인코더와 디코더로 모델이 구성되지만 RNN은 제거되었기에 RNN 처럼 문장의 순서를 고려할 수 없다. 이를 위해 각 문장의 단어들에 대한 위치를 표시하는 positional encoding을 사용한다.
다음은 논문에 나와있는 모델의 구성이다.
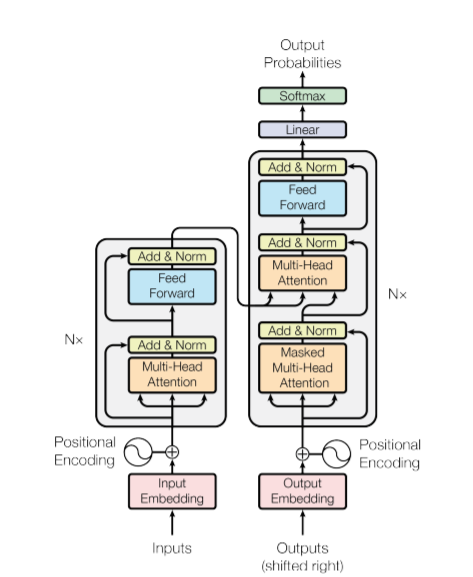
- 단어들에 대해 임베딩을 한 후 임베딩된 값들에 위치 인코딩 정보를 각각의 요소들에 더해줌으로써 각 단어들이 어떤 순서를 가지는지 네트워크가 알 수 있도록 한다.
- multi head attention에서 각 단어들이 문장 내 다른 단어들과 얼만큼 연관성을 가지는 지를 학습하도록 한다. 즉 어텐션을 통해 들어온 입력 문장들에 대해 문맥에 대한 정보를 학습하도록 한다. 예를 들어 input으로 You are perfect라는 문장이 들어왔다고 해보자. 그럼 multi head attention 에선 you가 are과 perfect와 어느정도의 연관성을 지니는지, are은 다른 두 단어와 어느정도의 연관성을 지니는 지 등의 연관된 정도를 측정한다.
- 성능향상을 위해 Add+Norm에서 잔여학습을 한다. 잔여학습은 attention 층에 들어오기 전의 입력값들을 attention층을 거쳐 나온 값들에 더하는 학습방식으로 네트워크 최적화 난이도를 줄임으로써 초기 학습 수렴 속도를 높이고 성능을 높여줄 수 있는 학습이다. 잔여학습에 대한 자세한 설명은 관련된 논문에 대해 설명한 영상을 참고하자. 잔여학습에 더해 정규화(normalization)까지 적용하여 출력한다.
- 3에서 나온 출력값을 피드포워드 층에 넣고 마찬가지로 잔여학습과 정규화 과정을 N layers에서 N번 반복한다.
- 마지막 N번 레이어에서 나온 값들을 디코더의 두번째 어텐션층에 넣어준다.
- 디코더에서도 마찬가지로 출력으로 나올 타겟텍스트에 대해 positional encoding을 해주고 attention층에 넣어준다 . 디코더에서는 두 개의 attention층을 사용하는데 그 중 첫번째 attention층에선 타겟 텍스트의 단어들이 서로 어떤 단어들과 연관성이 높은지 측정함으로써 타겟텍스트 문맥에 이해도를 높인다.
- 인코더의 마지막 층에서 나온 소스텍스트 정보들과 디코더의 첫번째 attention층에서 나온 정보들을 결합하여 타겟텍스트와 소스텍스트들의 단어 간 연관성을 측정한다. 예를들어 'You are perfect'가 소스텍스트이고 '너는 완벽하다'가 타겟텍스트이면 '너'가 어떤 영단어와 높은 연관성을 지니는지 측정한다.
- 마찬가지로 어텐션층에서 나온 값들을 피드포워드 층에 넣고 잔여, 정규화 학습을 수행한다. 이 과정을 N개의 layer층에서 반복한다.
- 각각의 디코더의 multihead attention에서 나온 값들을 모두 합친 값에 선형함수를 취해주고 softmax함수로 적합한 단어에 대한 확률값을 도출하여 타겟텍스트를 생성할 수 있다.
transformer의 모델 구조의 특징을 정리해보자.
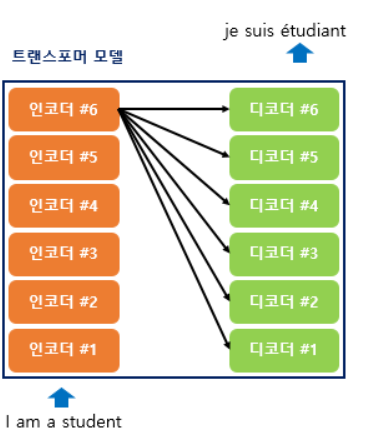
첫번째, 그림4와 같이 입력 값들을 한번에 인코더에 넣어주고 인코더의 마지막 출력값을 디코더의 두번째 attention층에서 모든 디코드 레이어에 입력함으로써 정보가 고루 반영될 수 있도록 만든다.
두번째, RNN에선 입력값들을 순서대로 하나씩 인코더에 넣어줬지만 트랜스포머에선 한꺼번에 입력 값들을 넣고 attention값을 병렬적으로 구할 수 있기에 일반적으로 RNN 보다 계산 복잡도가 낮다.
세번째, 디코더는 문장의 끝을 나타내는 <eos>가 나올 때까지 다수 반복하여 값을 출력한다.
네번째, 다수의 인코더와 디코더를 사용한다.
▷ Multi- head Attention
그럼 트랜스포머에서 보이는 multi head attention은 어떤 것인지 정리해보자.
이 구조를 이해하기 위해선 쿼리, 키, 값에 대한 개념을 먼저 알아야 한다.
- 쿼리 Query: 문장 단어 중 다른 나머지 단어들과의 연관성을 측정할 대상이 되는 단어이다.
- 키 Key: 쿼리와 연관성을 측정할 문장의 단어들이다. 예를 들어 'I love you'라는 문장이 입력으로 들어왔다고 하면 'I' 쿼리가 다른 단어들과 가지는 연관성을 알기 위해 'I love you'라는 키와의 연관성을 측정한다. 즉 특정 쿼리가 키에 대해 가지는 각각의 attention score를 측정한다.
- 값 Value: 쿼리와 키에서 나온 attention score에 실제 value 값을 곱해 attention value값을 구할 수 있다.

쿼리와 키가 입력으로 들어오면 행렬곱, 마스킹, 소프트맥스 함수를 취해 어텐션 스코어를 구하고 스코어에 value 값을 행렬 곱해줌으로써 attention value값을 구한다. 이러한 구조를 h개(head의 개수)의 서로 다른 v, k, q를 구성함으로써 h개의 다른 어텐션 컨셉을 학습하도록 만들어 다양한 특징을 학습할 수 있도록 해준다.
입력으로 들어온 행렬과 출력값의 행렬 차원이 같아야 하기 때문에 h개로 나눠진 어텐션을 모두 합치는 concat을 수행한 후 linear 함수를 취해준다.
디코더에서 특정 query에 대한 어텐션을 구해주기 위해 key 와 value는 인코더에서 받아와 연산을 수행한다.

쿼리와 키를 행렬곱 연산한 후 k의 차원의 제곱근으로 나눠 스케일링 한 후 소프트맥스 함수를 취해 쿼리의 키에 대한 확률값을 구해준다. 그리고 그 값에 V를 곱해줌으로써 어텐션을 얻을 수 있다.

여러 개의 헤드에 어텐션을 취해준 값들을 concat하여 입력 행렬과 같은 차원으로 만든 후 output matrix와 곱해 멀티헤드 어텐션 값을 구할 수 있다.
따라서 트랜스 포머의 동작원리는 다음 그림과 같이 정리할 수 있다.

추가적으로 위 동작과정에서 각 단어간 attention energy를 구한 행렬에서 특정 단어를 무시하고 싶을 경우 동일한 차원의 mask matrix에서 특정 단어에 해당하는 위치에 음수 무한의 값을 넣어 softmax 함수의 출력이 0에 가까워지도록 하여 무시할 수 있다.
▷ Positional encoding
각 입력에 대해 위치인코딩을 입력해 들어간다고하였는데 이 위치인코딩은 어떻게 연산되는 걸까?
위치인코딩은 다음과 같이 각 단어의 상대적인 위치 정보를 알 수 있는 주기 함수를 활용한 공식을 사용한다.
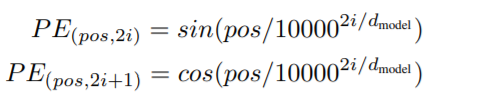
pos와 i가 단어의 임베딩 위치를 알려주는 요소로, pos는 어떤 단어를 가르키는지, i는 pos 단어 중 어떤 임베딩 위치를 가르키는 지를 알려준다. d(model)은 임베딩 차원이다.
i가 짝수일 때는 sin함수를, 홀수일때는 cos함수를 사용하여 표현한다. 위 공식을 활용해 구한 값들을 그림 7과 같이 임베딩에 더함으로써 위치 정보를 반영할 수 있다.
이번 포스팅에서는 최근 딥러닝 분야에 혁신을 가져다준 Attention is All you need 논문의 핵심 내용에 대해 공부하고 정리해보았다.
다음 포스팅에서는 해당 논문 내용을 따라 작성된 나동빈님의 코드를 실습하고 리뷰해보고자 한다.
'논문요약 및 정리' 카테고리의 다른 글
| SimCSE: Simple Contrastive Learning of Sentence Embeddings (0) | 2022.11.30 |
|---|---|
| XLNet: Generalized Autoregressive Pretraining for Language Understanding (0) | 2022.10.21 |
| BART(Bidirectional and Auto-Regressive Transformers) (0) | 2022.09.14 |
| Utilizing BERT for Aspect-Based Sentiment Analysis via Constructing Auxiliary Sentence (2) | 2021.07.21 |
| 리뷰의 의미적 토픽분류를 적용한 감성분석 모델 (0) | 2021.07.14 |