[2019 facebook ai]
Introduction
필자는 지금까지의 모델들은 주로 특정 end task(생성, span 예측)에만 초점맞춰져있다고 주장한다. (Bert는 주로 자연어 이해에, GPT는 단방향 모델로 자연어 생성에서 사용)
따라서 본 논문에선 더 다양한 범위의 end task를 수행할 수 있는 모델을 제안한다.
BART는 자연어 생성에 좀 더 효과적이지만 자연어 이해에서도 잘 작동한다. → GLUE, SQuAD에선 Roberta와 비슷한 성능을, 추상적인 대화와 질의응답, 요약 태스크에선 SOTA 모델이라고 한다.
뿐 만 아니라 BART는 번역 태스크에서도 새로운 방식을 제안한다. BART에서는 몇 개의 추가적인 트랜스포머 레이어를 쌓은 후, 해당 레이어들을 외국어를 노이징된 영어로 매핑하고 이를 다시 디노이징하는데 사용함으로써 BART가 강력한 번역모델로 동작하도록 했다.
기학습은 다음과 같은 단계로 이뤄진다.
- 텍스트에 노이징을 넣어준다. → 5가지 노이징 방법론을 실험해보았다고한다.
- 노이즈가 들어간 텍스트를 원래의 텍스트로 되돌리도록 학습한다.
Model
BART는 트랜스포머 아키텍처를 기반으로 한 노이즈 제거 오토 인코더로, 손상된 텍스트를 인코더에 입력하고 인코더에서 학습한 텍스트 표현을 디코더로 보내면 디코더에선 원래의 손상되지 않은 텍스트로 재구성한다.
양방향 인코더와 단방향 디코더로 이뤄지며 복원손실, 즉 원본텍스트와 디코더가 생성한 텍스트 간 크로스엔트로피 손실을 최소화하도록 학습된다.
Architecture
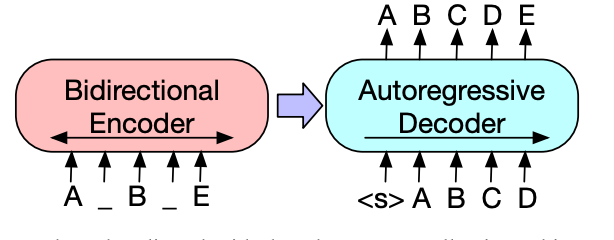
- base 모델: 인코더와 디코더에 각 6개의 레이어를 사용한다.
- large 모델: 인코더와 디코더에 각 12개의 레이어를 사용한다.
BERT와의 차이점은 다음과 같다.
- 디코더의 각 레이어는 인코더의 마지막 은닉층에 대해 cross-attention(encoder의 output을 k,v로 삼은 attention)을 수행한다. (반면 BERT는 인코더만 사용) → bert보다 약 10% 더 많은 파라미터를 가지게 됨
- BERT는 단어를 유추하기위해 추가적으로 feedforward network를 사용하지만, bart는 사용하지 않는다. BART는 인코더에서 학습한 임베딩을 디코더에 입력해 원래 문장으로 생성 및 재구성한다.


Pre-training BART
저자는 기학습될 데이터에 학습의 성능을 올릴 수 있는 최적의 노이즈를 찾기 위해, 여러 노이징 기법을 도입하여 실험해보았다.
- Token Masking
토큰을 무작위로 마스킹한다.
ex) 이건 첫 번째 예시 문장이다. 이 문장은 두 번째 예시이다. → 이건 [MASK] 번째 예시 문장이다. 이 [MASK] 두 번째 예시이다.
- Token Deletion
토큰을 무작위로 삭제한다. 모델은 토큰이 삭제된 위치를 찾아 그 위치에 적합한 토큰을 예측해야한다.
ex) 이건 첫 번째 예시 문장이다. 이 문장은 두 번째 예시이다. → 이건 번째 예시 문장이다. 이 은 두 번째 예시이다.
- Text Infilling 다양한 길이의 토큰 셋(span)을 하나의 마스크 토큰으로 대체한다. 토큰의 길이는 포아송 분포에 의해 결정된다. 모델은 얼마나 많은 토큰이 대체되었고, 동시에 그 토큰이 무엇인지 예측해야한다. ex) 이건 첫 번째 예시 문장이다. 이 문장은 두 번째 예시이다. → 이건 [MASK] 첫 번째 예시 문장이다. 이 [MASK] 예시이다.
- Sentence Permutation 문장의 순서를 무작위로 바꾼다. ex) 이건 첫 번째 예시 문장이다. 이 문장은 두 번째 예시이다. → 이 문장은 두 번째 예시이다. 이건 첫 번째 예시 문장이다.
- Document Rotation 주어진 문서에서 특정 단어를 무작위로 문서의 시작 토큰으로 정의하고, 해당 토큰 앞에 있는 단어들을 문서 뒤에 추가한다. 모델은 문서의 시작점을 찾아야한다. ex) 이건 첫 번째 예시 문장이다. 이 문장은 두 번째 예시이다. → 문장이다. 이 문장은 두 번째 예시이다. 이건 첫 번째 예시
Fine-tuning BART
- Sequence Classification Tasks
시퀀스를 분류하는 태스크에선 같은 입력 데이터를 인코더와 디코더에 입력한다.
BERT에서 [CLS]토큰으로 분류 태스크를 수행하는 것처럼 BART에서는 디코더의 마지막에 추가적인 토큰을 추가하고 해당 토큰을 multi-class linear classifier에 입력함으로써 분류 태스크를 수행한다.
- Token Classification Tasks 토큰 분류 태스크를 수행하기 위해 모든 문서를 인코더와 디코더에 입력한다. 디코더의 마지막 은닉 값, 즉 각 단어의 표현하는 값들을 토큰 분류에 사용한다.
- Sequence Generation Tasks BART는 autoregressive decoder를 사용하기 때문에 추상적인 질의 응답과 요약과 같은 생성 태스크를 수행할 수 있다. 인코더엔 입력 문장을 넣고 디코더는 문장을 autoregressive하게(자기 자신을 입력으로 하여 자신을 예측하는) 생성한다.
- Machine Translation
BART에선 단일 언어로 학습했기 때문에 다른 언어의 텍스트가 들어오면 이를 처리할 수 없다.
따라서 아래 그림과 같이 새로운 인코더를 추가해줌으로써 다른 언어의 text 정보를 학습된 언어의 text정보로 넘겨주어 위 문제를 해결할 수 있다.
새로운 인코더는 외국어를 BART에서 사용된 언어의 단어로 매핑하도록 학습되고, 학습된 결과(노이즈가 있는 타겟 언어)를 기존 기학습된 BART모델로 denoise 하도록 학습된다.
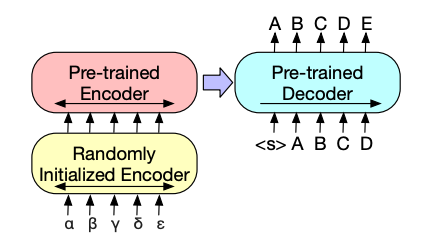
Comparing Pre-training Objectives
BART모델과 성능을 비교할 모델로 다음 모델들을 선택했다.
본 논문 이전에 제안된 강력한 사전학습 모델들을 사용했고, 모델마다 learning rate 조정이나 layer normalization 사용과 같이 미세한 변화를 줌으로써 성능을 향상시키고자 했다.
- Language model GPT와 유사하게 left-to-right transformer 언어 모델이다.
- Permuted Language Model 1/6 토큰들을 샘플링한 후 무작위 순서로 해당 토큰들을 생성하는 모델이다.
- Masked Language Model BERT에서와 같이 15% 토큰을 마스킹하고, 마스킹된 토큰들을 예측하도록 학습된다.
- Multitask Masked Language Model MLM에 additional self-attention mask를 추가하여 학습한다.
- Masked Seq-to-Seq 토큰의 50%를 포함한 span을 마스킹하고 해당 마스킹 토큰을 예측하기 위해 학습된다.
실험은 두가지 갈래로 수행했는데, 소스 텍스트를 인코더에 넣고 디코더에서 타겟 텍스트를 도출하는 방법에서는 BART가 가장 잘 작동했지만, 소스 텍스트를 타겟의 prefix에 추가해 디코더에 넣고 타겟 파트의 로스만 계산한(only decoder 모델) 방법에서는 다른 모델들이 더 잘 작동했다고 한다.
생성 모델의 성능을 직접적으로 비교하기 위해 perplexity를 계산했다.
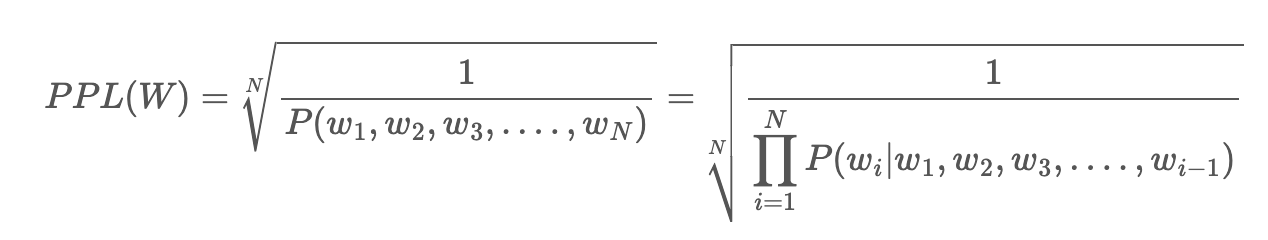
minimizing perplexity == maximizing probability perplexity 계산과정
Tasks
- SQuAD wikipedia에서 따온 본문과 질문이 주어지면 본문으로부터 정답에 해당하는 text span을 찾는 Question Answering 태스크이다. 본문과 문제를 연결하여 인코더의 인풋으로 사용하고, 이들을 디코더에 패스함으로써 정답(본문에서 정답에 해당하는 문자열의 시작점과 끝점)을 예측하도록 한다.
- MNLI
두개의 문장에 대한 분류 태스크로 이전 문장의 관계가 어떻게 성립되는지 예측하는 태스크이다.
두 문장에 문장의 끝을 알리는 EOS 토큰을 추가한 후, 두 문장을 합쳐서 인코더와 디코더에 넣는다. EOS토큰은 문장 관계를 분류하는데 사용된다.

- ELI5
긴 형식의 abstractive question answering 태스크로 질문과 문서를 합친것을 인코더로 넣고 답변을 생성하도록 학습된다.

- XSum 뉴스 요약 태스크 (많이 함축된 요약 생성)
- ConvAI2 대화의 답변에 대한 생성 태스크로, context와 persona를 입력으로 준다.
- CNN/DM 뉴스 요약 태스크
Results
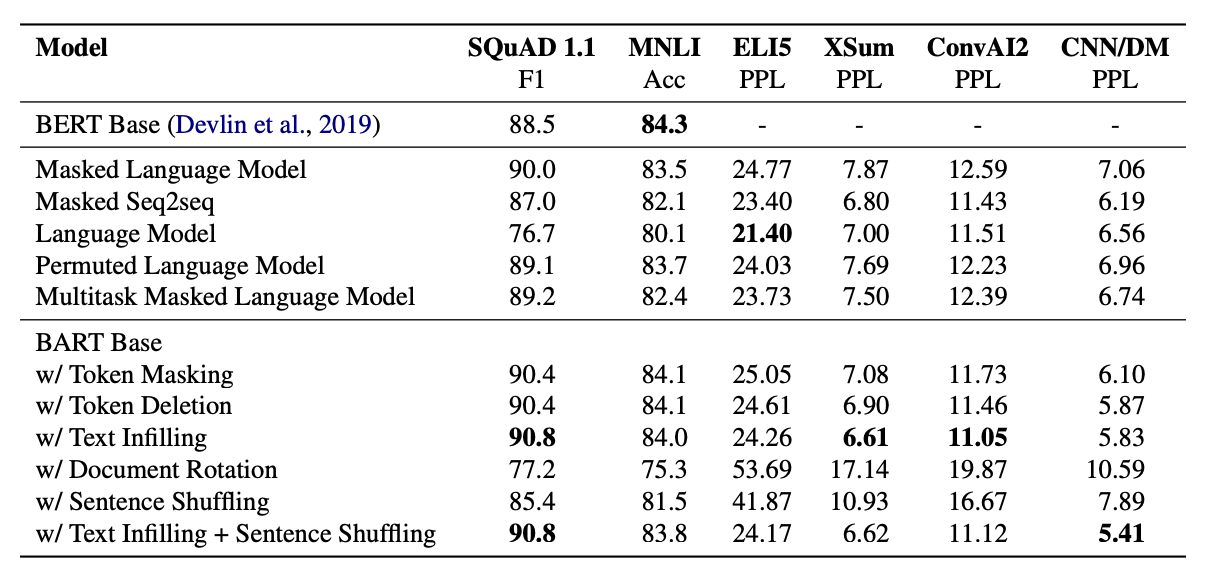
위 결과에서 시사하는 바는 다음과 같다.
- 사전학습의 효율성은 수행하는 태스크에 매우 크게 의존한다.
- 토큰 마스킹은 중요하다. Document Rotation, Sentence Shuffling은 가장 좋지 않은 성능을 보인 반면, Token Deletion, Masking, Text Infilling은 좋은 성능을 보였다. 이 중 생성모델에선 Deletion이 Masking보다 더 좋은 성능이 나왔다.
- BART는 ELI5처럼 출력결과가 인풋과 느슨하게 연결되어 있는 태스크에선 성능이 좋지 못하다. ELI5에선 유일하게 BART보다 다른 순수 언어 모델이 더 좋은 성능을 보였기 때문이다.
- ELI5를 제외하고는, text infilling 기법으로 마스킹한 BART모델의 성능이 거의 모든 태스크에서 좋은 성능을 보인다.
- SQuAD에선 양방향 인코더의 성능이 좋았다. 미래의 정보가 정답에 중요한 영향을 미치기 때문이다.
- 생성 모델에선 left-to-right pre-training이 더 좋은 성능을 보인다. MLM이나 Permuted Language Model은 생성태스크에서 가장 좋지 않은 성능을 보였다.
Large-scale Pre-training experiements
사전 학습된 모델의 스케일이 클수록 다운스트림 태스크에서 더 좋은 성능을 보여왔다.
따라서 모델의 스케일이 클 수록 더 좋은 성능을 보일 것이라는 가정하에 다른 모델들과의 성능 비교 테스크를 수행해보았다.
- Experimental setup
인코더와 디코더엔 각 12개의 레이어를 사용했으며 은닉층의 사이즈는 1024로 설정했다. 배치 사이즈는 8000으로, 500000번의 스텝으로 모델을 학습시켰다.
BPE로 토큰화를 진행했고 노이징 기법은 text infilling+sentence permutation기법을 적용했다. 각 문서에서 30%의 토큰에 마스킹을 진행했다.
160gb에 달하는 텍스트 데이터를 동일하게 사용하여 학습했다.
Discriminative Tasks
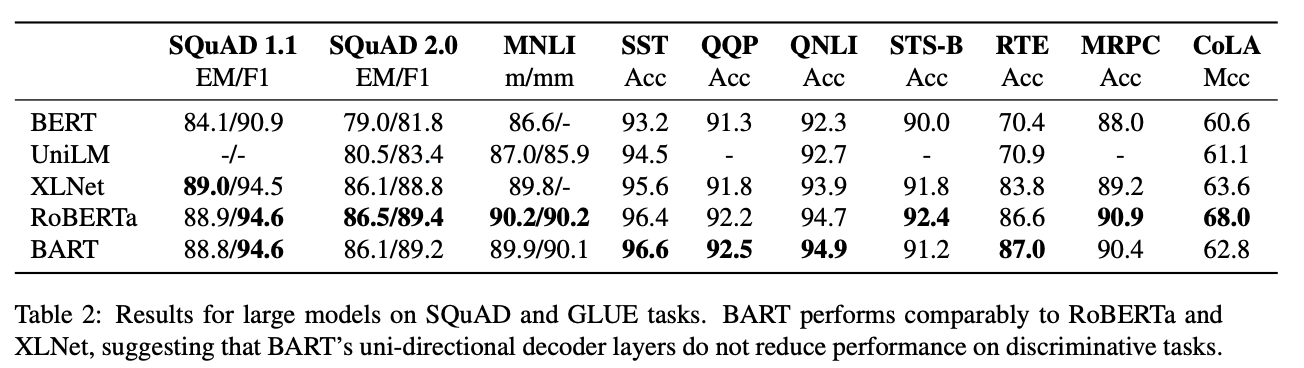
SQuAD와 GLUE 데이터셋에 실험해본 결과 전반적으로 BART는 Roberta와 성능적으로 큰 차이가 없었다.
이로 미뤄보아, BART가 분류문제에서 타 모델보다 유의미하게 성능이 향상되진 않는다는 것을 알 수 있다.
Generation Tasks
Summarization
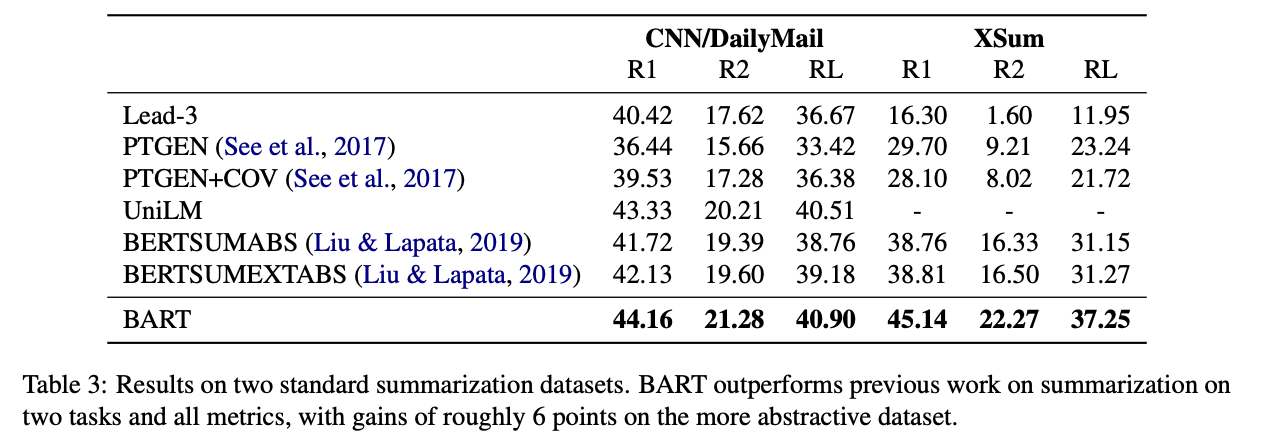
CNN/Daily mail은 생성된 요약 텍스트와 소스 텍스트가 비슷하다. 반면 XSum은 매우 추상적인 요약 데이터셋이다.
BART는 두 태스크에서 모두 다른 모델의 성능을 능가하는 결과를 보여주었다. → BART는 요약 태스크에서 좋은 성능을 발휘한다.
Dialogue
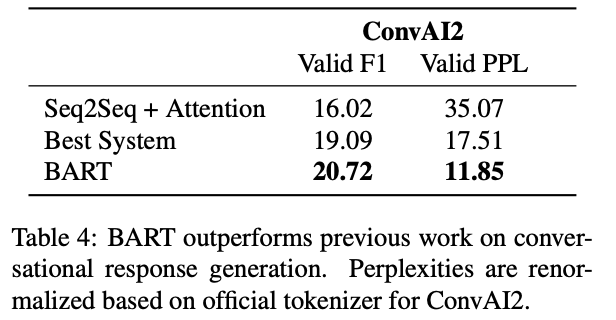
ConvAI2에서 모델은 이전 대화 문맥 뿐 만 아니라 주어지는 화자(persona)의 발화 특징도 캐치하여 답변을 생성해야한다.
BART는 해당 태스크에서 역시 다른 생성모델의 성능을 능가했다.
Abstractive QA
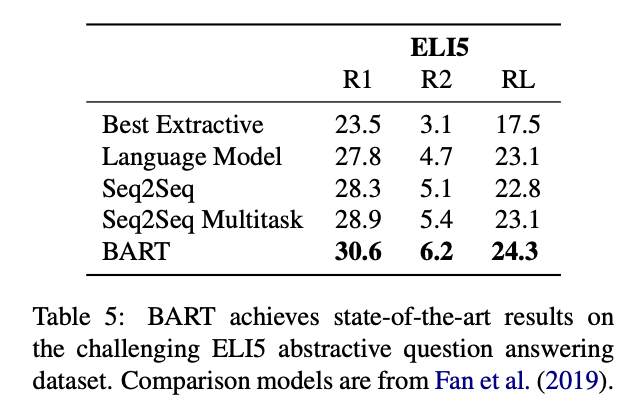
자유형식의 긴 문장을 생성할 때의 성능을 시험할 수 있는 데이터셋이다. (정답이 문제에서 잘 정의되지 않아 답을 유추하기 어려운 데이터 셋임)
BART가 ROUGE에서 가장 좋은 성능을 보였다.
Translation

Romanian에서 영어로 번역하는 데이터셋으로 실험했다.
이전 절에서 설명되었다싶이, 6개 트랜스포머 레이어로 이뤄진 인코더를 통해 Romanian을 기존 인코더에서 BART가 영어로 denoise할 수 있는 형태의 표현으로 매핑시켜서 학습시켰다.
- Fixed BART: 매핑하는 여섯개의 레이어만 학습하고 나머지 파라미터는 freeze
- Tuned BART: 모든 파라미터를 한번 더 학습
back translation으로 증강한 데이터셋으로 실험한 결과, 기존 transformer baseline보다 성능이 높았다.
Qualitative Analysis

- BART는 요약태스크에 큰 강점을 보인다.
- 요약 문장을 정성적으로 평가한 결과, 유창하고 문법적인 문장이 생성되었으며 내용 또한 사실적이고 정확했음을 확인했다.
→ BART는 자연어 이해와 생성을 결합하여 학습할 수 있는 모델임을 알 수 있다.
Reference
https://neptune.ai/blog/bert-and-the-transformer-architecture
https://github.com/huggingface/transformers
 https://choice-life.tistory.com/55
https://choice-life.tistory.com/55
Uploaded by N2T