728x90
star schema는 분석 성능을 높이고 사용자가 이해하기 쉬운 단순한 분석 환경을 구축하기 위해 필요하며,
snowflake schema는 복잡한 데이터 간의 관계를 체계적으로 정리하고, 데이터 중복을 막아 저장 효율을 높이기 위해 필요한 구조이다.
대표적으로 활용되는 스키마의 특징을 알아야 프로젝트 상황(속도가 중요한지, 관리가 중요한지)에 맞는 아키텍처를 설계할 수 있으므로,
우선 이 두 가지 스키마에 대해 정리해보고자한다.
star schema
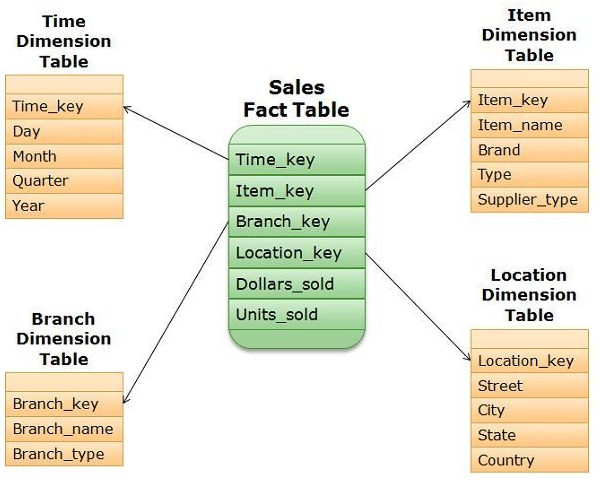
- 구조: 중앙의 팩트 테이블을 중심으로 여러 차원 테이블이 직접 연결된 단순한 형태임.
- 특징: 데이터가 비정규화되어 있어 중복이 존재하지만 테이블 간 조인이 적음.
- 제품 테이블 하나에 '브랜드'와 '공급타입' 정보가 모두 들어 있음. 데이터 분석가가 "어떤 공급타입이 가장 많이 팔렸나?"라고 물었을 때, 단 한 번의 조인으로 결과를 얻을 수 있어 성능이 매우 빠름.
- 장점: 쿼리 구조가 단순하여 응답 속도가 빠르며, 데이터 마트나 단순 분석에 유리함.
- 단점: 데이터 중복으로 인해 저장 공간을 많이 차지하며 무결성 관리가 어려움.
- 예를 들어, 두개의 city (경기도 수원시, 경기도 용인시) 가 같은 State (경기도) & Country (한국) 값을 가지기 때문에, Location Dimension Table 에 '경기도', '한국' 값이 중복되어 적재됨.
snowflake schema
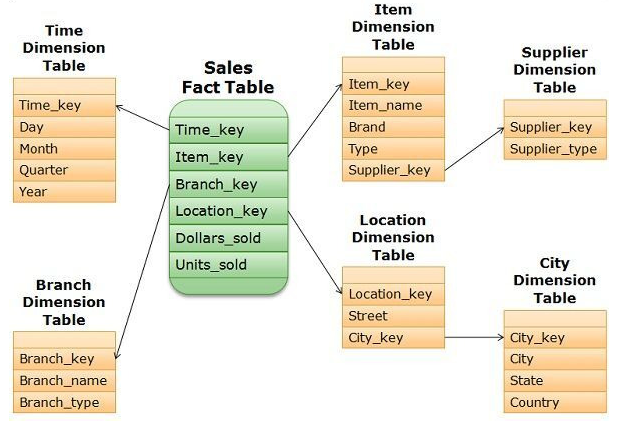
- 구조: 스타 스키마의 변형으로, 차원 테이블을 다시 하위로 분리하여 정규화한 형태임.
- 특징: 데이터 정규화를 통해 중복을 완전히 제거함.
- 제품' 테이블에는 제품명만 있고, 공급 타입 정보는 별도의 Supplier Dimension 테이블에 저장됨. 데이터 중복은 없으나, "어떤 공급타입의 제품이 많이 팔렸나?"를 알기 위해 여러 번의 조인을 거쳐야 하므로 쿼리가 복잡해짐.
- 장점: 저장 공간을 효율적으로 사용하며 데이터 무결성 유지 및 관리가 용이함.
- 두 개의 city (경기도 수원시, 경기도 용인시) 가 다른 City_Key값을 가지고, 중복될 수 있는 State & Country 값은 City_key를 키값으로 하는 City Dimension 테이블에 별도 관리되기 때문에 관리가 용이함.
- 단점: 다수의 조인이 발생하여 쿼리 복잡도가 높고 실행 속도가 상대적으로 느림.
star scshema VS snowflake schema
| 비교 항목 | 스타 스키마 | 눈송이 스키마 |
| 정규화 여부 | 비정규화됨 (중복 있음) | 정규화됨 (중복 없음) |
| 구조 복잡도 | 단순하고 직관적임 | 복잡하고 계층적임 |
| 쿼리 성능 | 조인이 적어 빠름 | 조인이 많아 상대적으로 느림 |
| 저장 효율성 | 낮음 (공간 낭비 발생) | 높음 (공간 최적화 가능) |
| 유지보수성 | 데이터 수정 시 번거로움 (ex. 카테고리명 변경 시 모든 제품 행 수정 필요) |
데이터 일관성 관리가 쉬움 (ex. 카테고리 테이블의 한 행만 수정하면 됨) |
| 주요 용도 | - 소규모 프로젝트나 빠른 성능이 최우선인 분석 환경 - 비즈니스 리포트 별 데이터 마트 등.. |
- 데이터 양이 방대하고 데이터의 정확한 관리가 필수적인 환경 - 대규모 데이터 웨어하우스용 |
스타 스키마는 성능과 단순함에, 눈송이 스키마는 데이터 정합성과 저장 효율성에 강점이 있으므로,
조직의 데이터 규모와 분석 환경에 맞춰 적절한 모델을 선택하는 것이 중요함.
참고 자료
https://sunrise-min.tistory.com/entry/Star-schema%EC%99%80-Snowflake-schema-%EB%B9%84%EA%B5%90
728x90
'Data > 데이터 엔지니어링' 카테고리의 다른 글
| [dbt] Jinja in dbt (0) | 2026.02.22 |
|---|---|
| [dbt] dbt는 무엇이고, 언제 활용될까? (0) | 2026.02.17 |
| OLAP & Data Warehouse (0) | 2026.02.08 |
| [BigQuery] BigQuery With Partitioning & Clustering (0) | 2026.02.08 |
| ELT vs ETL 언제 사용하면 좋을까? (0) | 2026.02.02 |