부스트 코스의 딥러닝 2단계: 심층 신경망 성능 향상시키기 강의를 수강하며 내용정리한 포스팅입니다.

▶ 하이퍼파라미터
신경망을 학습할때 튜닝해야하는 하이퍼파라미터는 학습률, 모멘텀, 아담 최적화알고리즘의 ε과 β1, β2, 층 수, 은닉 유닛 숫자, 학습률 감쇠(learning rate decay), 미니 배치 사이즈 등 무척 많다. 직관에 따라 하이퍼파라미터 튜닝의 중요도를 순서대로 정리하면 다음과 같다.
1순위: 학습률
2순위: 모멘텀, 미니배치 사이즈, 은닉 유닛 수
3순위: 층 수, 학습률 감쇠
(아담 알고리즘의 ε은 10^-8, β1은 0.9, β2는 0.999를 항상 사용하지만 원한다면 튜닝해도 좋다.)
▶ 딥러닝에서의 하이퍼파라미터 튜닝
하이퍼파라미터의 수가 적을 때는 그리드 서치를 통해 최적의 하이퍼파라미터를 쉽게 구할 수 있었지만 파라미터의 수가 많은 딥러닝 모델의 경우 그리드 서치를 통해 일일히 최적값을 찾는 것은 비효율적이고 힘든 일이다.
그렇다면 딥러닝 모델에선 최적의 하이퍼 파라미터를 어떻게 찾을까?
랜덤하게 돌려봐라.
튜닝해야 할 하이퍼파라미터가 많은 딥러닝 모델에선 어떤 하이퍼파라미터가 학습에 중요한 영향을 끼치는 지 확신할 수 없기 때문에 최적의 하이퍼파라미터를 찾을 때 주로 랜덤하게 하이퍼파라미터를 찍어보는 방법을 사용한다. 랜덤하게 찍은 하이퍼파라미터 값으로 모델을 돌려보았을 때 가장 좋은 성능이 나왔던 하이퍼파라미터를 선택하게 된다.
정밀하고 랜덤하게 돌려봐라.
정밀화 기법은 처음에 랜덤하게 찍었던 하이퍼파라미터들 중에서 가장 성능이 잘나왔던 하이퍼파라미터가 있는 공간에서 더 많은 랜덤한 점을 찍어 더 세세하게 값들을 조정하는 기법이다.

그림 1에선 하이퍼 파라미터가 3개인 모델에 대한 최적값을 찾기 위해 랜덤하게 점을 찍은 파라미터 값들로 모델을 돌린다. 그리고 모델이 가장 최고 성능이 나온 하이퍼파라미터를 정한다. 그림 1에선 빨간색 점이 가장 최고 성능을 나타낸 파라미터 값들인데, 우리는 이 파라미터 값의 주변에 위치한 점들 역시 비슷하게 좋은 성능을 내는 값들임을 유츄할 수 있다. 즉 빨간 점 주변에 더 좋은 성능을 낼 수 있는 점이 존재하고 있을 확률이 있기 때문에 그 주변 공간을 zoom in 하여 랜덤한 점들을 다시 찍어 모델을 돌려봄으로써 파라미터에 대한 세밀한 조정을 수행할 수 있다.
▶ 하이퍼파라미터 튜닝 시 적절한 척도 선택하기
선형 척도 내에서 무작위로 뽑는 것이 합리적인 파라미터들(은닉유닛 수, 은닉층의 수 등)이 존재한다. 하지만 선형 척도로 무작위 선택을 해서 튜닝할 경우 비효율성을 초래하는 하이퍼파라미터들이 존재한다.
그 일례로 학습률 파라미터에 대해 얘기해보자.
가장 적합한 학습률을 찾기위해 0.0001에서 1사이의 값들을 균일하게 랜덤으로 골라 모델을 돌려본다고 하자. 그런데 선형척도로 값을 랜덤하게 찍으면 0.0001에서 0.1사이엔 10%의 값들이 찍히는 반면 0.1에서 1사이엔 90%의 점들이 찍힐 것으로 예상할 수 있다. 즉 0.1에서 1사이에 점들이 몰려 찍히기 때문에 비합리적인 랜덤서치가 될 가능성이 다분하다.
따라서 이런 경우 선형척도보다는 로그척도에서 랜덤하게 값을 찍는 것이 더 합리적인 방법이 될 수 있다. 0.0001에서 1의 범위를 로그척도로 잘라보면 그림2와 같을 것이다.
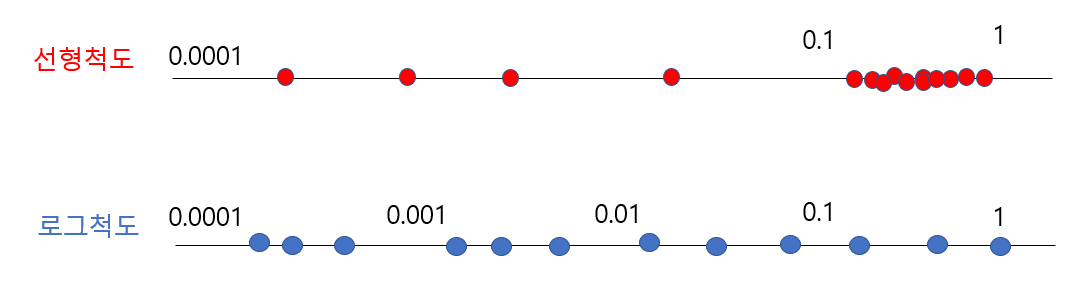
볼 수 있다싶이 선형 척도는 0.1에서 1사이에 값이 몰려 찍히는 반면 로그척도에서는 범위에 맞게 균등한 분포 모양을 띌것이다. 이를 대력적으로 코드로 나타내면 다음과 같다.
alpha= 10**r
r= -4*np.random.rand()
즉 0에서 -4 사이의 값을 균일하게 무작위로 고르고 학습률 alpha에서 10의 지수로 바꿔 사용할 수 있다.
해당 포스팅에선 로그척도가 더욱 효율적인 하이퍼파라미터들 중 학습률에 대해서만 얘기해보았다. 참고한 영상에서는 β 파라미터에 대해서도 얘기하고 있으니 궁금하면 원본 영상을 참고해보도록 하자.
▶ 하이퍼파라미터 튜닝 계획
최적의 하이퍼파라미터는 데이터가 계속 바뀌고, 알고리즘이 바뀌는 등 상황에 따라 얼마든지 달라질 수 있기 때문에 초반에 찾았던 하이퍼파라미터는 시간이 지날수록 모델에 적합한 하이퍼파라미터가 될 수 없다. 따라서 계속해서 하이퍼파라미터를 재평가하는 과정이 필요하다. 이러한 지속적인 하이퍼파라미터 튜닝을 위한 방법으론 크게 두가지 방법을 사용한다.
▷ 판다 접근(baby sitting one model)
판다 접근 방법은 하나의 모델에 대해 매일 성능을 지켜보며 학습 속도를 조금씩 바꾸는 방법으로, 컴퓨터의 자원이 많이 필요하지 않거나 적은 숫자의 모델을 한번에 학습시킬 수 있을 때 사용한다.
해당 접근 방법은 우선 초기에 하이퍼파라미터를 세팅해두고 모델의 성능을 계속해서 지켜보다가 성능이 좋으면 학습속도를 늘리고 성능이 좋지 않으면 속도를 낮추는 등의 조치를 지속적으로 취하는 방법이다.
판다가 한마리의 자식을 지극정성으로 돌보고 살아남을 수 있도록 케어하는 것처럼 해당 접근 방식도 하나의 모델에 대해 케어하기 때문에 판다 접근이라고 이름 붙였다고 한다.
▷ 캐비어 접근(Training many models in parallel)
캐비어 접근은 컴퓨터의 자원이 충분히 많아 여러 모델을 한번에 학습 시킬 수 있을 때 사용하는 접근 방법이다.
캐비어 접근에서는 우선 특정 하이퍼파라미터를 가진 모델을 며칠에 거쳐 스스로 학습하고 성능을 측정하도록 한다. 그와 동시에 다른 파라미터를 가진 모델들을 역시 며칠에 거쳐 스스로 학습하도록 한다. 그리고 동시다발적으로 측정된 많은 모델들 중 가장 성능이 좋은 하이퍼파라미터를 선택하여 사용하는 방식이다.
물고기가 1억개의 캐비어 알을 품어두고 하나 혹은 그 이상의 알이 살아남을 수 있도록 지켜보듯이 해당 접근 방식 역시 여러개의 모델을 돌려보고 그 중 성능이 가장 좋은 모델을 선택하는 방식을 취하기에 캐비어 접근이라는 이름을 붙였다고 한다.
▶ 튜닝 라이브러리
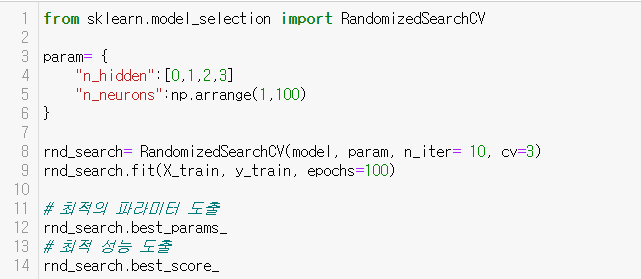
sckit-learn에서는 하이퍼파라미터의 랜덤 튜닝을 도와주는 RandimizedSearchCV를 제공한다.
다음 코드는 은닉층 수와 뉴런 수에 대해 랜덤튜닝하는 과정을 간략히 보여주는 코드이다.
이외에도 많은 회사들이 구글 클라우드 AI 플랫폼의 하이퍼파라미터 튜닝 서비스 등 하이퍼파라 최적화 서비스를 제공하고 있다고 한다.
'Data > 머신러닝 & 딥러닝' 카테고리의 다른 글
| 순전파와 역전파 (0) | 2022.01.20 |
|---|---|
| 그레디언트와 경사하강법 (0) | 2021.08.06 |
| RNN과 게이팅 (0) | 2021.08.03 |
| 심층 신경망 성능 향상시키기(2)/ 편향, 분산 (0) | 2021.08.03 |
| 심층 신경망 성능 향상시키기(1) / Train, Dev, Test sets (0) | 2021.08.02 |