▶ 네트워크 모델의 발전
파라미터 수가 많으면 overfitting의 문제가 발생한다. 따라서 네트워크 모델은 이 파라미터 수를 줄여 일반화 성능을 올리는 방향으로 발전해왔다. 이와 동시에 네트워크 깊이는 키움으로써 더 딥한 학습을 가능케하는 방향으로 발전되어왔다.
해당 포스팅에서는
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- DenseNet
순으로 모델의 발전과정을 짚어보고자 한다.
▶ AlexNet

- 네트워크가 2개로 나눠져있다. 당시 GPU숫자가 부족했기 때문에 2개의 GPU를 최대로 사용하기 위해 이러한 구조가 나온것이라고 한다.
- 11 x 11의 input을 사용한다. 이 필터를 사용하면 하나의 kernal이 볼 수 있는 영역은 커지지만 상대적으로 파라미터는 더 많이 사용하게 되는 문제점이 있다. 이후 차례로 5 x 5, 3 x 3 필터를 사용했다.
- 5개의 convolutional layer와 3개의 dense layer로 구성되어있다.
▷ 왜 성공했는가?
- 효과적인 activation function인 ReLU를 사용
- ReLU: linear model의 속성은 보존하면서 vanishing gradient problem문제를 어느정도 극복한 함수이다.
- 2개의 GPU 사용
- Local Response Normalization 사용: 입력공간에서 response가 많이 나오면 몇가지를 죽임으로써 sparse한 activation이 나오게끔 한다.
- Data augmentation사용
- Dropout 사용
LRN을 제외하곤 지금 보면 일반적인 것들이지만 당시에 해당 요소들은 당연한 것이 아니었다. 즉 Alexnet은 딥러닝 모델의 성능이 잘 나오기 위한 기준점이라고도 볼 수 있다.
▶ VGGNet
- 3 x 3 convolution filter만 사용한다. Alexnet에선 총 세가지 타입의 필터를 사용했다.
- 1 x 1 convolution for fully connected layer를 사용한다.
- Dropout(p=0.5)를 사용한다.
▷ 왜 3 x 3 convolution을 사용했는가?
- convolution의 크기가 커지면 하나의 filter를 찍었을 때 고려될 수 있는 이미지의 크기가 커진다. 즉 convolution을 찍었을 때 고려할 수 있는 입력의 special dimension인 receptive field가 커진다.
- 3 x 3 필터를 두번 걸쳐 만든 output은 5 x 5 필터를 한번 걸쳐 만들어진 output의 receptive field와 같은 값을 가진다.

- 3 x 3필터를 두번 걸쳤을 때의 파라미터 개수와 5 x 5를 한번 걸쳤을 때의 파라미터 개수를 비교해보면, 3 x 3 필터를 두번 걸친 경우의 파라미터 수가 더 적다.

따라서 같은 receptive filter를 도출하는 과정에서 5 x 5를 한번 사용하는 것보다 3 x3 을 두번 사용하는 것의 경우에 파라미터 개수를 더 줄일 수 있다는 장점이 있다.
▶ GoogLeNet

- 22 layers로 구성된다.
- 비슷하게 생긴 네트워크 구조가 내부에서 여러번 반복되어 network in network(NiN)라고 불린다.
- Inception blocks를 가진다. Inception block이란 하나의 입력에 대해 여러개로 퍼졌다가 다시 합쳐지는 구조를 말한다.

- Inception block사이에 1 x 1 convolution을 넣어줌으로써 전체적인 파라미터 개수를 줄이고자 했다.
- 또한 해당 방법은 vgg와 alexnet에서 동일한 사이즈의 필터커널을 적용했던 것과 차이가 있기에, 좀 더 다양한 종류의 특성을 도출해 낼 수 있다고 한다.
▷ 왜 1 x 1 convolution을 추가하면 파라미터 수가 줄어드는가?
- 결론적으로 해당 방법을 사용하면 채널 방향으로 차원을 축소해 파라미터의 숫자를 30% 정도 줄일 수 있다.
3차원에서의 합성곱 연산
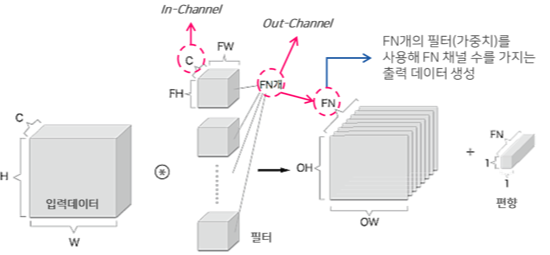
- 1 x 1 convolution을 추가로 넣었을 때와 넣지않았을 때의 계산과정을 예시로 들어보았다.
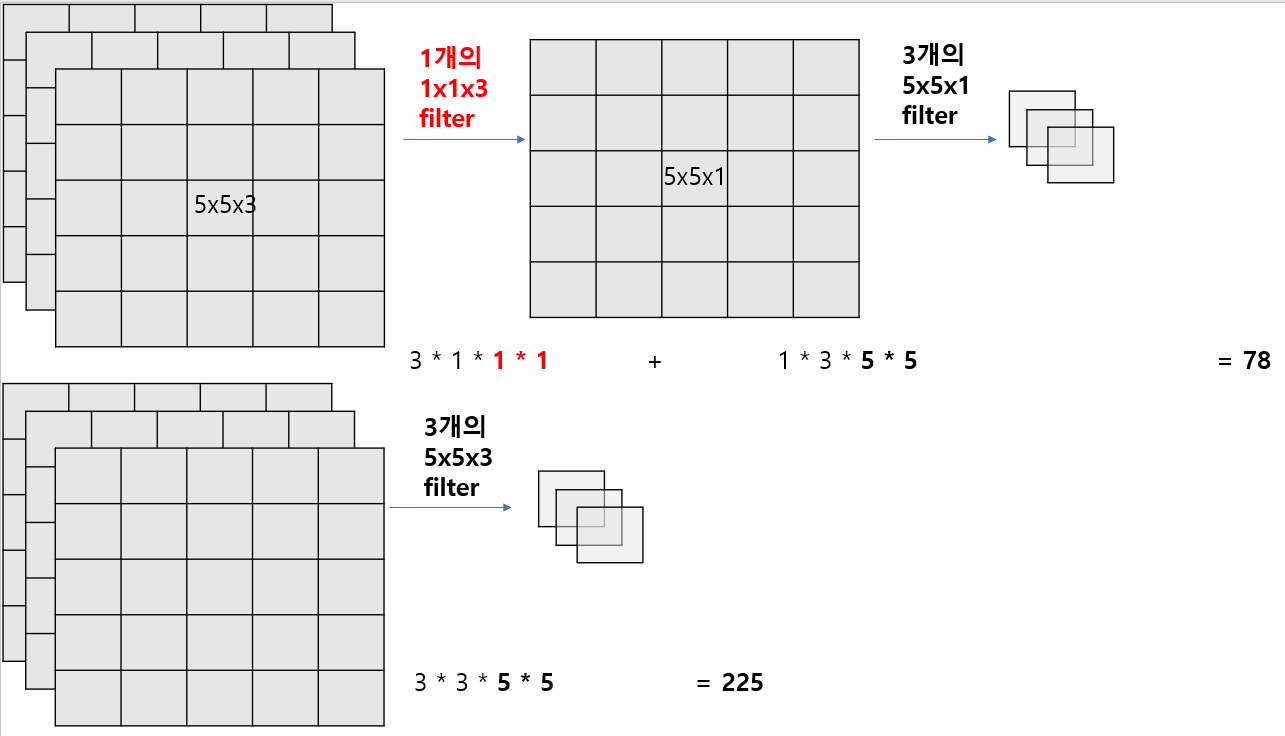
- 1x1 conv를 중간에 추가해줌으로써 채널의 개수를 줄여, 결국 전체적인 파라미터의 수를 줄이는 결과를 낼 수 있다.
- 파라미터의 수를 줄인다는 것은 결국 네트워크의 층을 더 깊게 구성할 수 있도록 한다.
▶ ResNet
- 신경망이 깊어질 수록 학습시키기 어려워지는 문제점을 해결하기 위해 고안된 모델이다.
- Residual connection을 추가함으로써 차이 값에 대헤서 학습하도록 한다.
- skip connection은 입력값인 x에 출력값인 f(x)를 더한 값을 활성화 함수에 넣어 학습시키는 방법이다.

- 궁극적으로 위 구조가 신경망을 어느정도 깊게 쌓아도 성능이 향상되는 모델을 만들 수 있도록 해주었다.
ResNet의 블록구조는 다음과 같다.
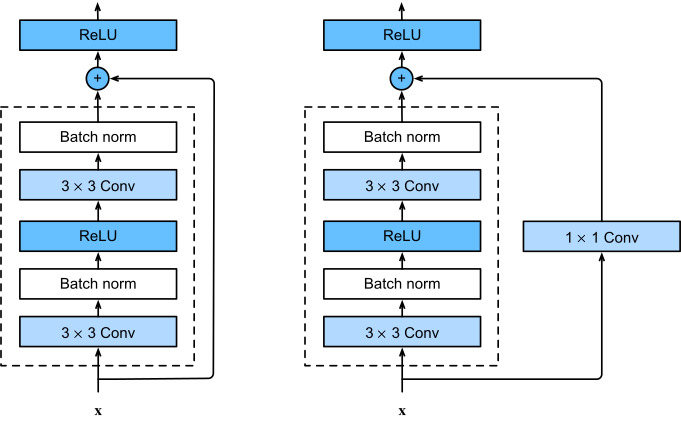
- 1x1 convolution을 추가해준 이유는 입력과 출력의 채널 수를 맞춰주기 위함이다.
- 1x1 conv로 채널을 줄이고 -> 그 후 3x3 conv를 적용해줌으로써 receptive field를 키우고 -> 다시 1x1 conv로 원하는 채널로 맞춰줌으로써, 파라미터 수를 줄이고 네트워크를 깊게 쌓을 수 있는 전략을 사용했다.
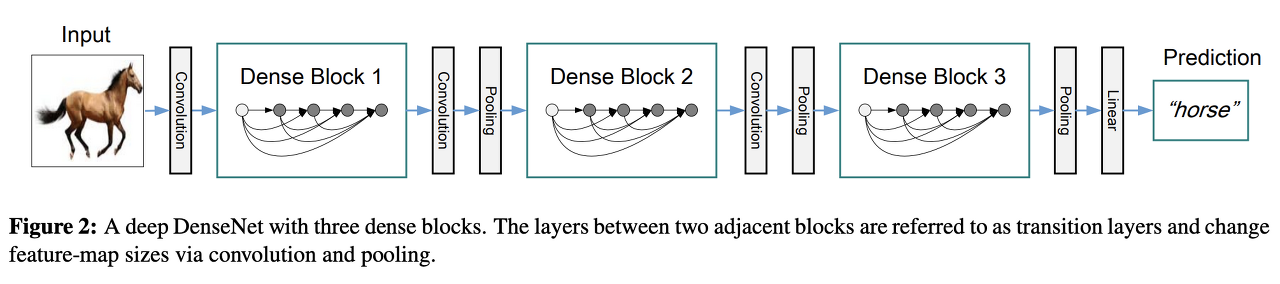
▶ DenseNet
- ResNet이 x와 f(x)를 더해주는 방식이라면 DenseNet은 둘을 붙여주는 방식이다.
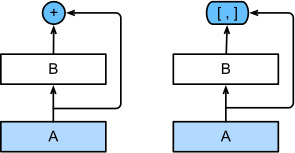
- 그러나 이를 계속해서 붙이다보면 다음 그림과 같이 채널 수가 증가하고 동시에 파라미터 수도 증가하게 된다.
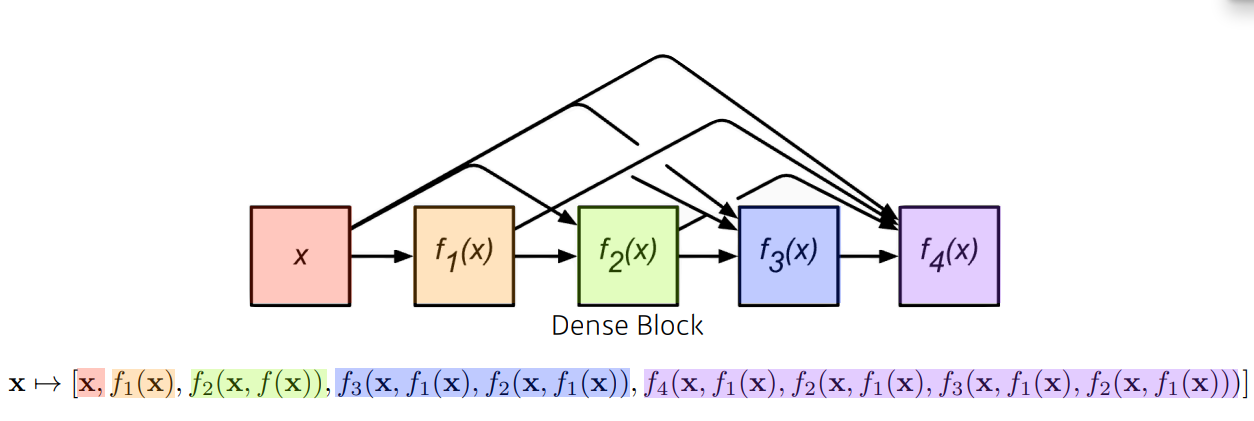
- 따라서 DenseNet은 늘어난 채널 수를 감소시키기 위해 다음 그림과 같이 중간중간 Transition Block (1x1 Conv, 2x2 AvgPooling)을 넣어준다.
▶ 모델의 발전
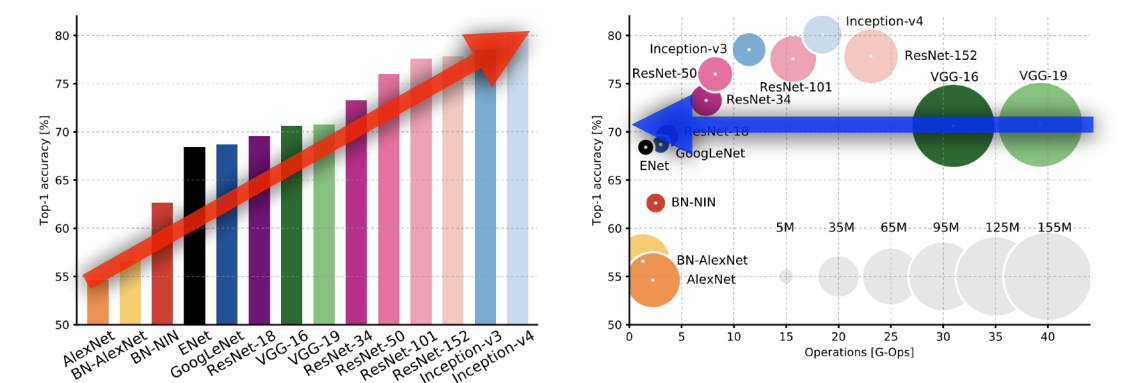
- 포스팅에 정리한 모델 순대로 파라미터의 수는 작아지지만 성능은 점점 증가한다는 것을 알 수 있다.
- 마지막에 소개한 ResNet 혹은 DenseNet모델을 사용했을 때 웬만하면 좋은 성능을 낼 수 있기 때문에 해당 모델들을 취사선택해서 많이 사용한다고 한다.
▶ Reference
'Data > 머신러닝 & 딥러닝' 카테고리의 다른 글
| Imbalanced dataset metric [cohen-kappa score] (0) | 2023.06.02 |
|---|---|
| Object Detection model - R CNN부터 Fast(er) R CNN까지 (0) | 2022.02.10 |
| Partial Dependence Plot (PDP) 란? (1) | 2022.02.04 |
| OOM (Out Of Memory) 해결 방법 (2) | 2022.01.27 |
| Custom Dataset tutorial - Fashion MNIST (0) | 2022.01.25 |