다음 도표는 딥러닝을 활용한 이미지 내 객체 검출(Object Detection) 모델의 milestone을 찍은 것이다.
최근으로 올수록 새로운 모델들이 점점 많아지는 것을 볼 수 있다..
오늘은 이 많은 모델들 중 2014 ~ 2016 년까지 발전해온 R-CNN계열 모델인,
- R-CNN (2014)
- Fast R-CNN (2015)
- Faster R-CNN (2016)
에 대해서 정리해보려고 한다.

우선 해당 모델들을 이해하는 데 필요한 개념 먼저 짚고 가보려고 한다.
▶ 사물인식 방법
이미지 내에서 사물을 인식할 때 대표적으로 다음 네가지 방법이 존재한다.
- Classification : 하나의 이미지를 입력으로 받은 후 해당 이미지가 어떤 클래스에 해당하는지 분류하는 방법이다.
- Classification + Localization : 이미지가 어떤 클래스에 해당하는지 분류함과 동시에 그 이미지(고양이)가 이미지의 어느 부분에 위치하는지 bounding box로 구분해내는 방법이다.
- Object Detection : 다수의 사물이 존재하는 이미지에서 각각의 사물의 위치와 라벨들을 분류하는 방법이다.
- Instance Segmentation : 이미지 내에 존재하는 각각의 사물에 대해 픽셀단위로 구분하는 방법이다. 하나의 픽셀이 어떤 라벨에 위치하는 픽셀인지 분류하는 방식이다.
▶객체 검출 방식
객체를 검출하는 방식은 다음과 같이 두가지 방식으로 나뉜다.
- 2 - Stage Detector
Faster R-CNN이 사용하는 방식이다.
순차적으로 물체의 위치를 찾고 (Localization) 해당 물체가 어떤 라벨에 속하는지 분류 (Classification)한다.
1) Region Proposals: 이미지에서 사물이 존재할법한 위치를 찾아 나열한다. (Localization)
2) Feature Extractor: 각각의 위치에 대한 feature를 추출한다. (Classification)
3) Classification: 추출한 feature를 대상으로 라벨을 분류한다.
4) Regression: 이미지 내의 bounding box의 위치에 대한 정보를 재조정한다.
- 1 - Stage Detector
YOLO에서 사용하는 방식이다.
Localization과 Classification문제를 한번에 수행한다. 따라서 Faster RCNN보다 정확도는 낮지만 속도는 훨씬 빠르다고 한다.
1) Feature Extractor
2) Classification
3) Regression
▶R-CNN 계열 모델
R-CNN은 모두 2 - stage Detector방식을 사용한다.
이름에서도 짐작할 수 있다싶이, R-CNN에서 Fast R-CNN, Faster R-CNN으로 갈수록 속도는 빠르고 성능은 더 좋아진다. 이는 모델 학습과정에서 사용되는 구조의 단순화, GPU의 사용, end-to-end로의 아키텍처 변경으로 이러한 발전이 가능했다.
> End to end 네트워크란?
역전파 알고리즘을 통해 모델의 모든 매개 변수를 학습시켜 네트워크 가중치를 최적화 할 수 있는 네트워크를 end to end network라고 한다.
▶ Region proposals란?
이미지에서 객체가 있을 법한 위치를 찾아 bounding box로 골라내는 과정이다.
R-CNN은 이 과정에서 총 2000개의 object proposal(객체 후보군)을 생성한다.
1) Sliding Window
다음과 같이 이미지에서 다양한 형태의 window(anchor box)를 가지고 이미지를 sliding하며(이미지를 훑으며) 물체가 존재하는지 확인하는 과정이다.
- 그러나, Region Proposal은 다양한 크기의 window를 가지고 많은 부분에 대해 물체존재 여부를 확인해야하기 때문에
- 또한, CPU에서 이미지를 input으로 넣어 탐색하기 때문에
속도가 느리다는 단점이 있다.
Faster R-CNN은 해당 방법을 사용하지만 CPU가 아닌 GPU에서 작동될 수 있도록 구조가 설계되었기 때문에 빠른 속도로 task를 수행할 수 있다.
2) Selective Search
Region proposal 방법으로, 인접한 region(bounding box)과의 유사성을 측정하여, 유사성이 크면 해당 region들을 통합해나가는 방법이다.
R-CNN과 Fast R-CNN에서 객체를 검출하기 위해 사용되는 방법이다.

위와 같이 이미지내에서 모든 region proposal을 뽑아낸 후, 유사한 bounding box끼리 통합해서 자잘한 Region을 줄이는 방식이다.
Selective search의 알고리즘은 다음과 같다.

- 초기화 단계에서 Felzenszalb and huttenlocher's graph-based image segmentation 알고리즘을 적용하여 이미지 내 region들을 나눈다.
- 모든 이웃한 region들과의 유사성을 계산해 S 집합에 넣는다.
- S집합에 유사도 계산 값이 남아있다면 다음과 같은 과정을 계속 반복한다.
- S집합에서 가장 큰 유사도를 가진 세트 ri,rj에 대한 연산을 진행한다.
- ri,rj를 rt로 통합한다.
- ri,rj를 S 집합에서 제거한다.
- rt와 다른 이웃들과의 유사도를 계산한다.
- 통합된 rt들이 있는 R집합에서 object location boxes를 추출한다.
기본적으로 해당 알고리즘은 CPU에서 수행되도록 코드가 작성되었기 때문에 이미지 한장에 2초 정도의 시간이 소요된다고 한다.
▶ Object Detection 성능 평가 방법 - Intersection over Union
두 bounding box가 겹치는 비율을 말한다.
따라서 정답 박스와 예측한 박스가 겹치는 부분의 비율이 높을 수록 정답에 가깝게 박스가 형성되었다고 볼 수 있다.
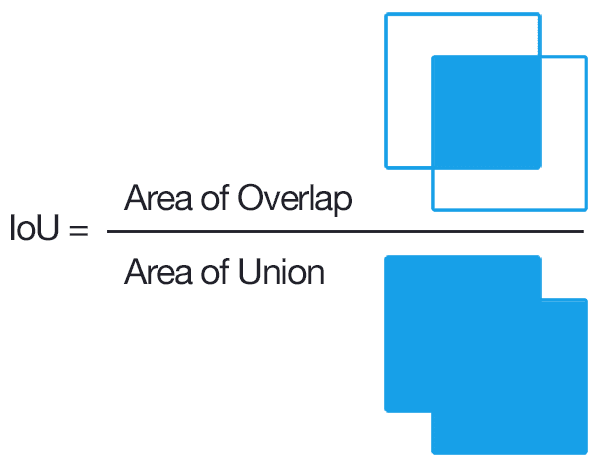
예시로,
mAP@0.5는 IOU가 50% 이상일 때 정답으로 판정하겠다는 의미이다. 즉 정답과 예측의 bounding box가 겹치는 부분이 50% 이상이어야 정답으로 인정된다.
▶ R-CNN (2014)
이미지 내에 존재하는 다수의 객체 클래스를 분류할 수 있게 해준 R-CNN계열 모델의 첫번째 모델이다.
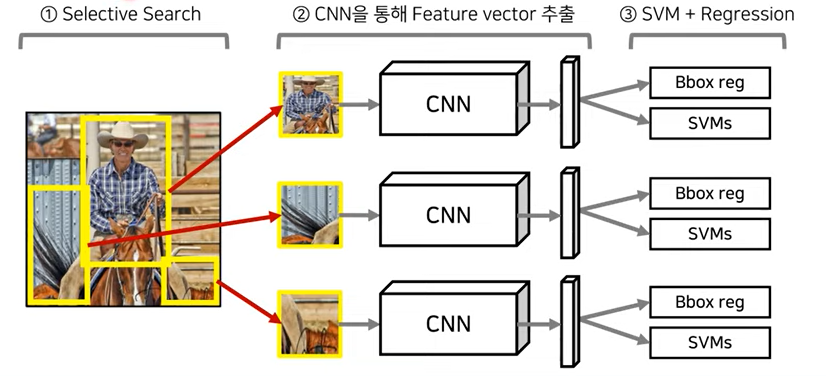
1. 우선 selective search를 통해 region proposals를 2000개 뽑아낸다.
2. 그 후 뽑아진 모든 region들을 동일한 크기로 warping(찌뿌러트린) 후 각각을 CNN에 넣어 feature vector를 추출한다.
3. 벡터를 Bbox regressor에 넣어 물체가 어떤 위치에 존재하는지 더 정확히 예측하고자 한다.
또한 그렇게 추출한 벡터들을 binary SVMs에 넣어 해당 벡터가 어떤 클래스에 해당하는 것인지 분류한다.
R-CNN 모델이 발표된 당시엔 분류 문제에 SVM모델을 많이 사용하고 있었다고 한다. 특히 다중 분류를 위해선 각 클래스에 대해 독립적으로 훈련된 binary SVM을 사용했다고 한다. 따라서 R-CNN에선 해당 모델을 통해 클래스를 분류한다.
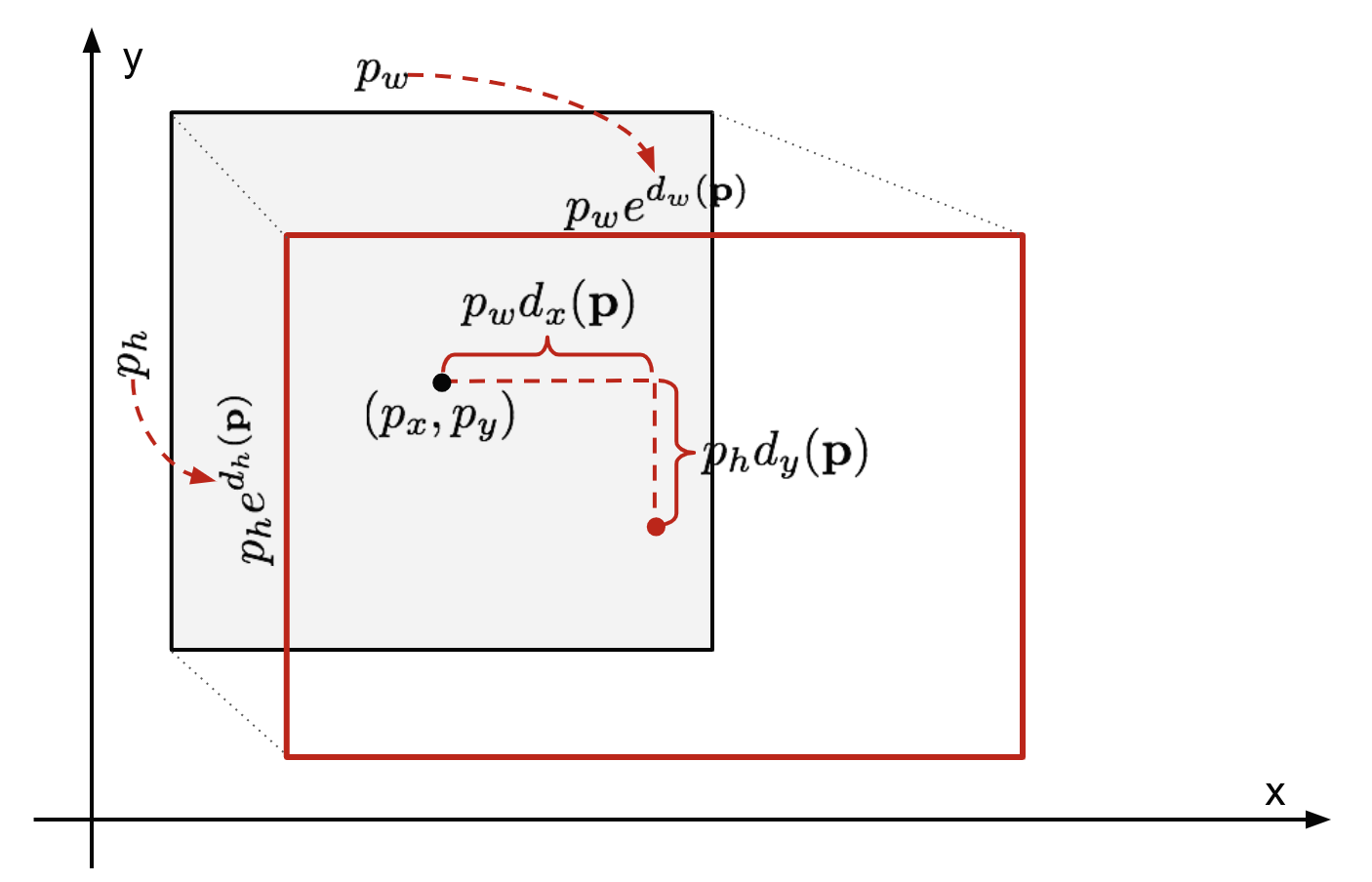
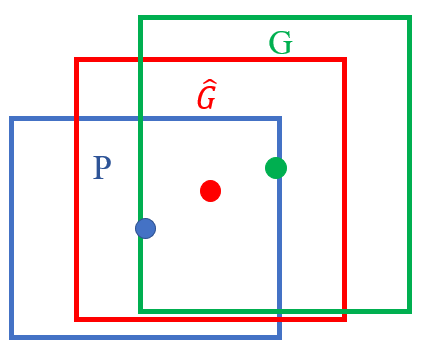
▷ Bounding Box Regression이란?
localization의 성능을 높이기 위해 사용하는 방법이다.
bounding box의 위치를 중앙점 좌표 (Px,Py에 Ph만큼의 높이, Pw만큼의 너비를 가지고 있다고 예측했다고 하자.
이때 우리가 맞춰야하는 실제 bbox의 위치는 G=(Gx,Gy,Gw,Gh)에 있다.
우리는 우리가 예측한 위치인 P가 실제 위치인 G와 최대한 가까워지도록 네개의 데이터를 예측해 조정해야한다.
즉 우리는 Linear regression으로 4개의 파라미터를 학습해서 예측한 ˆg가 G와 가까워질 수 있도록 한다.
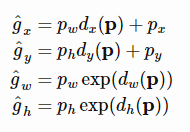
▷ R-CNN의 한계
- Selective Search부터 모두 CPU에서 학습이 수행되어 속도가 느리다는 단점이 있다.
- 2000개의 Region Proposals를 모두 CNN에 넣어 2000번의 CNN연산을 수행해야하기 때문에 학습과 평가에 많은 시간이 걸린다.
- 또한 해당 모델에서 CNN은 feature vector만 추출하는 고정된 아키텍처로, SVM과 bbox reg과 분리되어 있다. 따라서 End-to-End로 학습시켜 성능을 더욱 향상시킬 수 없다는 한계가 있다.
▶ Fast R-CNN (2015)
R-CNN과 동일한 selective search를 사용해 Region Proposal 을 뽑아내지만, 이미지를 CNN에 한번만 넣어 feature map을 생성한다는 데에서 차이가 있다.
또한 ROI pooling기법을 적용하며 라벨 분류 시 SVMs이 아닌 softmax를 활용한다는 점이 다르다.
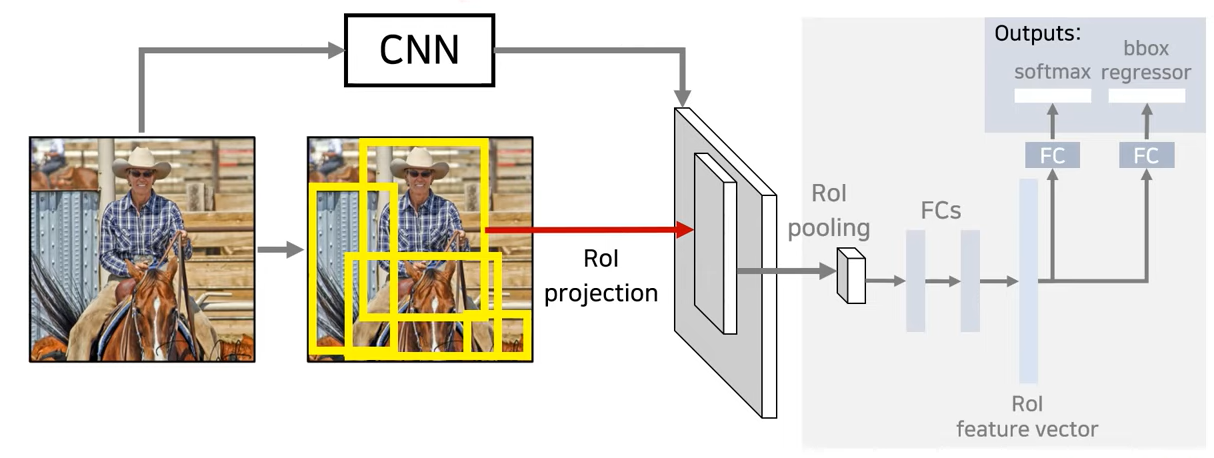
- feature map 정보에는 원본이미지에서의 위치 정보도 포함하고 있다.
따라서 feature map으로 ROI(Region Of Interest) projection을 하여 물체가 존재할 법한 위치를 feature map에서 찾도록 만들 수 있다.
- feature map 상에 사물이 존재할 법한 위치에서, ROI pooling을 통해 필요한 정보를 추출한다.
- 추출된 feature vector으로 softmax를 통해 라벨을 분류하고, bbox regressor을 통해 정확한 bounding box의 위치를 예측한다.
회색 사각형 부분은 feature map 상에서 개별 ROI마다 행해지는 과정이다.
▷ ROI Pooling이란?
분류를 위해 Fully Connected Layer를 이용해야하기 때문에 고정된 크기의 벡터를 생성할 필요가 있다.
따라서 해당 모델에선 max pooling방법을 이용해 각 ROI에 대한 일정한 크기의 벡터를 생성한다.
위 예시와 같이 2x2의 벡터를 생성한다고 하면 ROI feature map(빨간 네모)을 2x2로 적절히(최대한 같은 비율을 가지도록) 나눈 후, 나눠진 각 영역에서 가장 큰 벡터를 2x2벡터에 넣어준다.

▷ Fast R-CNN의 한계
CNN 1회 사용,ROI pooling, softmax, ROI projection을 통해 R-CNN보단 빠른 성능을 갖게되었지만, 여전히 Region proposal 부터 CPU를 사용하기 때문에 속도가 느리다는 한계가 있다.
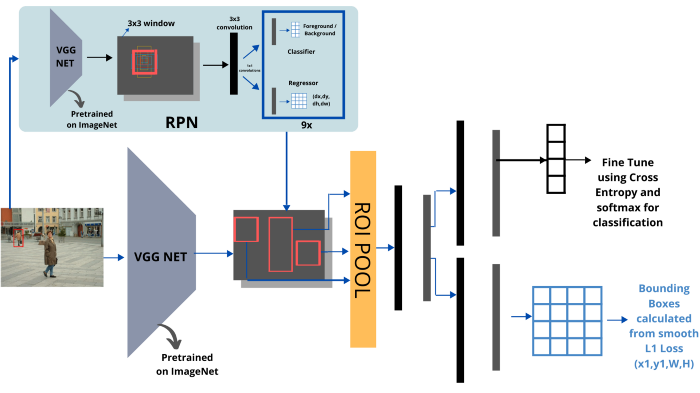
▶ Faster R-CNN (2016)
Fast R-CNN의 단점을 개선한 모델로, RPN(Region Proposal Network)를 통해 Region Proposal작업을 GPU장치에서 수행하도록 하여 학습속도를 높였다.
또한 end to end model로 성능까지 확보할 수 있었던 모델이다.
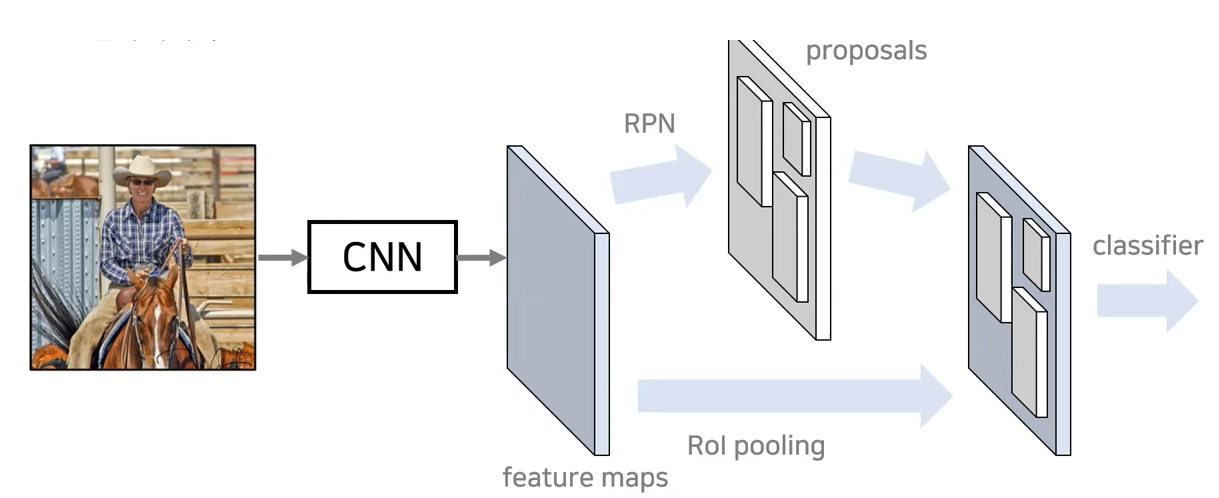
- CNN을 통해 이미지에서 feature vector를 추출한다.
- RPN을 통해 feature map에서 물체가 있을 법한 위치를 표시한다.
- 해당 위치들을 중심으로 라벨 분류와 bbox regression을 진행한다. classifier 부분은 Fast R-CNN모델과 동일한 구조를 사용한다.
RPN과 classifier 등 모든 작업에 대해서 이미지에 대해 처리를 수행하기 때문에 feature vector를 추출하는 CNN(vgg기반의 네트워크)을 공유할 수 있다는 장점이 있다.
따라서 출력부터 입력까지 end to end learning이 가능하기 때문에 모델이 예측한 출력값에 따라 CNN부터 가중치를 재조정하는 backpropagation을 할 수 있다.
▷ Region Proposal Networks란?
feature map에서 물체가 있을 법한 위치를 Sliding Window기법으로 예측하는 방법이다.
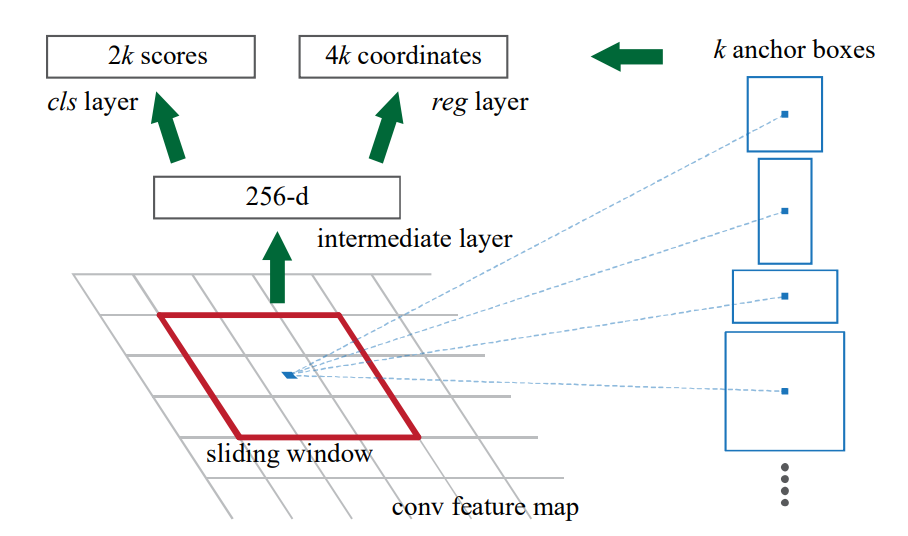
- K개의 anchor box로 feature map에서 이미지를 훑으며, 각 위치에 대해 256차원의 intermediate feature를 뽑는다.
- cls layer에서 해당 intermediate feature에 물체가 있는지 없는지를 분류한다. 또한 물체가 존재하는 위치를 정확히 찾기 위해 reg layer를 거쳐서 bounding box 중간점의 x,y 좌표, weight, height값을 출력한다.
다시 RPN구조를 포함해 Faster R-CNN을 시각화하면 다음과 같다.
▶ Reference
참고영상
https://arxiv.org/pdf/1506.01497.pdf
https://medium.com/zylapp/review-of-deep-learning-algorithms-for-object-detection-c1f3d437b852
'Data > 머신러닝 & 딥러닝' 카테고리의 다른 글
| Imbalanced dataset metric [cohen-kappa score] (0) | 2023.06.02 |
|---|---|
| CNN 모델 훑어보기 (0) | 2022.02.08 |
| Partial Dependence Plot (PDP) 란? (1) | 2022.02.04 |
| OOM (Out Of Memory) 해결 방법 (2) | 2022.01.27 |
| Custom Dataset tutorial - Fashion MNIST (0) | 2022.01.25 |