
▶ 렐루(Recified linear unit)
렐루는 최근에 등장한 신경망의 활성화 함수로 최근 딥러닝 혁신의 상당수를 가능케 해준 활성화함수이다. 시그모이드부터 탄젠트 함수까지 해결되지 않았던 기울기 소실문제를 해당 함수로 해결할 수 있었다.
공식을 먼저 알아보자.

이전 포스팅에서 보았던 함수와는 달리 엄청나게 간단한 공식이다. 해석하면 렐루 함수는 x가 음수면 0을, x가 양수이면 x값을 출력하는 함수이다.
따라서 ReLU함수는 y=x라는 직선 부분과 0 이하의 부분을 0으로 출력하는 부분으로 이뤄져있다.
▷ 구현
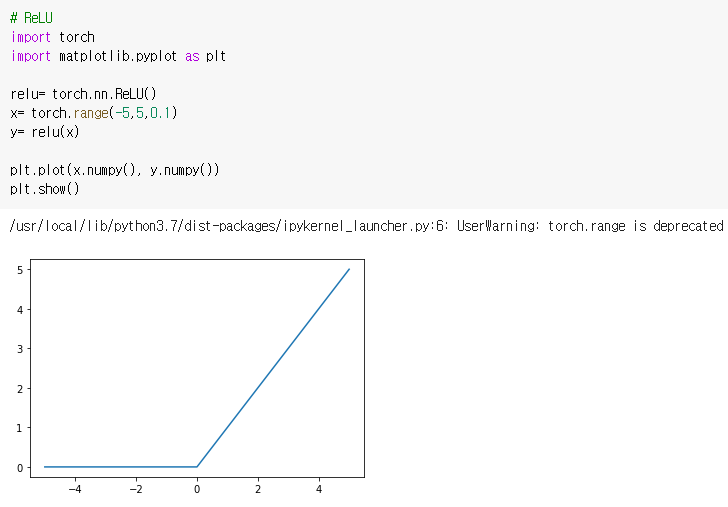
- 이렇게 간단한 공식인만큼 계산복잡도가 낮아져 깊은 신경망에서 학습속도를 개선시키는 효과가 있다.
- 시그모이드, 탄젠트함수와 마찬가지로 비선형 함수이고 음수에선 0, 양수에선 y=x값으로 전구간에 미분값이 존재하기 때문에 학습이 가능한 함수이다.
▷ 그렇다면 ReLU가 어떻게 기울기 소실문제를 해결했다는 걸까?
시그모이드 함수는 도함수에서 0에서 1사이의 작은 값을 계속 곱하면서 점점 그레디언트가 소실되는 문제가 발생했다. 하지만 렐루함수는 그림에서 볼 수 있다시피 미분값이 1이기 때문에 그레디언트 소실문제가 발생하지 않고 학습효과가 계속 지속될 수 있다.
이처럼 단순하면서 시그모이드함수의 문제를 해결할 수 있기 때문에 시그모이드 함수를 대체하여 많이 사용되고 있다.
▷ 죽은 렐루 문제
그러나 렐루 함수의 문제는 신경망의 특정 출력이 0이 되면 여태까지 학습하여 곱했던 그레디언트 값에 0을 곱하게 됨으로써 값을 0으로 만든다는 점이다. 이를 '죽은 렐루'문제라고 칭하기도하는데 이 문제를 해결하기 위해 변형함수인 Leaky ReLU와 PReLU(Parametirc ReLU)함수가 등장했다.
▶ Leaky Relu

leaky relu는 0보다 작거나 같을 때 0을 곱하는 것이 아닌 x에 0.01을 곱한 작은 양의 기울기를 사용하도록 하여 죽은 렐루 문제를 해결하고자 했다.
▶ PReLU

PRelu는 x가 양수일 땐 마찬가지로 x값을 그대로 도출하고 그 외엔 ax값을 도출하는데 여기서 a값은 다른 신경망 매개변수와 함께 학습되는 파라미터이다.
PReLU를 구현하면 다음과 같다.

0 이전에는 학습 매개변수 a가 곱해져 조금씩 증가하다가 0부터는 y=x 직선형태를 가진다.
'Data > 머신러닝 & 딥러닝' 카테고리의 다른 글
| 신경망의 기본 구성 요소(6)/ 손실함수 (2) | 2021.07.20 |
|---|---|
| 신경망의 구성요소(5)/ 활성화 함수- 소프트맥스 (0) | 2021.07.20 |
| 신경망의 기본 구성요소(3)/ 활성화 함수- 하이퍼볼릭 탄젠트 (0) | 2021.07.19 |
| 신경망의 기본 구성요소(2)/ 활성화함수- 시그모이드 (0) | 2021.07.19 |
| 신경망의 기본 구성요소 (1)/ 퍼셉트론과 논리게이트, 파이토치 구현 (2) | 2021.07.19 |